mirror of
https://github.com/domainaware/parsedmarc.git
synced 2026-07-05 16:25:09 +00:00
* Drop base_reverse_dns_types.txt; sortlists.py now reads types from README.md The .txt file duplicated the README's industry list and introduced drift risk — twice in the project's history we had to add types to the .txt only because the README had been updated independently. Make the README the single source of truth. - Add `<!-- types-list:start -->` / `<!-- types-list:end -->` HTML comment markers around the bullet list in parsedmarc/resources/maps/README.md. Markers don't render in GitHub's preview. - New `load_types_from_readme()` in sortlists.py parses the bullet items between the markers and returns them. Errors clearly if the README is missing or the markers are absent. - Delete base_reverse_dns_types.txt. - Fix a pre-existing typo in README precedence rule 4: `Web Hosting` → `Web Host` (matches the canonical type used in 4,176 map rows). Smoke test: feeding a row with a bogus type still triggers the validator (`'NotARealType' is not an allowed value for 'type'`), confirming the README-derived list flows through identically. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com> * sortlists.py: normalize README types-list block in place Before validating the map, the validator now sorts the <!-- types-list:start --> / <!-- types-list:end --> block in README.md alphabetically (case-insensitively), trims leading and trailing whitespace from each item, and deduplicates case- insensitively, rewriting the README in place if any of those need fixing. Errors clearly when two entries differ only by casing (which would otherwise silently lose one). Adding a new category is now just inserting a `- New Type` line anywhere inside the markers — `sortlists.py` will tidy it on the next run. Same shape as how the validator already normalizes known_unknown_base_reverse_dns.txt and psl_overrides.txt. The pure read path is preserved as `load_types_from_readme()` for callers that don't want a side-effecting rewrite (tests, downstream tooling). Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com> * Stop shipping maintainer scripts; bump to 9.11.2 The exclude list in [tool.hatch.build] was originally meant to keep maintainer-only batch tooling under parsedmarc/resources/maps/ out of the wheel and sdist (it lists `find_bad_utf8.py`, `find_unknown_base_reverse_dns.py`, the renamed-and-removed `sortmaps.py`). The list never grew when new tools were added, so `collect_domain_info.py`, `classify_unknown_domains.py`, `detect_psl_overrides.py`, `detect_rebrands.py`, and `sortlists.py` all started shipping in distributions despite contributing nothing to runtime functionality. Replace the per-file basename list with a single glob pattern: parsedmarc/resources/maps/[!_]*.py The leading-`_` exception keeps `__init__.py` shipping (required so that `importlib.resources.files(parsedmarc.resources.maps)` can locate the bundled CSV/TXT data files), while excluding any other .py file under that directory — including future maintainer scripts that haven't been written yet. Drop the now-redundant per-file entries from the exclude list: `find_bad_utf8.py`, `find_unknown_base_reverse_dns.py`, and the already-removed `sortmaps.py`. The non-.py exclusions stay (`base_reverse_dns.csv`, `unknown_base_reverse_dns.csv`, `README.md`, `*.bak`). Verified with `hatch build`: - Wheel under parsedmarc/resources/maps/: __init__.py + 3 data files (CSV/TXTs), no maintainer .py - sdist matches - Clean-venv install of the built wheel loads 298 PSL overrides and `get_base_domain('host01.netlify.app')` returns `netlify.app` Bump to 9.11.2 since this changes shipped artifacts. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com> --------- Co-authored-by: Sean Whalen <seanthegeek@users.noreply.github.com> Co-authored-by: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
parsedmarc
![]()
![]()


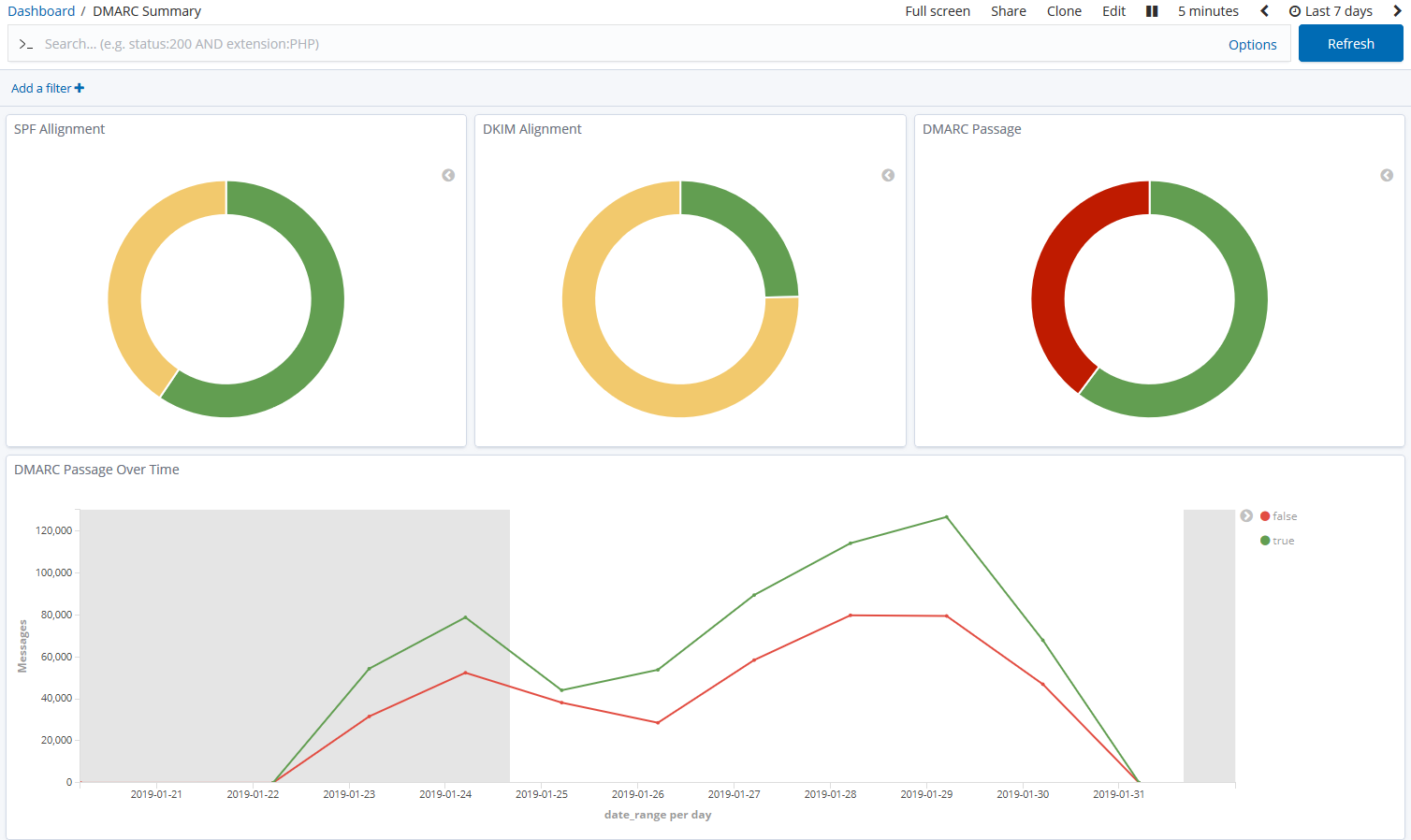
parsedmarc is a Python module and CLI utility for parsing DMARC
reports. When used with Elasticsearch and Kibana (or Splunk), it works
as a self-hosted open-source alternative to commercial DMARC report
processing services such as Agari Brand Protection, Dmarcian, OnDMARC,
ProofPoint Email Fraud Defense, and Valimail.
Note
Domain-based Message Authentication, Reporting, and Conformance (DMARC) is an email authentication protocol.
Sponsors
This is a project is maintained by one developer. Please consider sponsoring my work if you or your organization benefit from it.
Features
- Parses draft and 1.0 standard aggregate/rua DMARC reports
- Parses forensic/failure/ruf DMARC reports
- Parses reports from SMTP TLS Reporting
- Can parse reports from an inbox over IMAP, Microsoft Graph, or Gmail API
- Transparently handles gzip or zip compressed reports
- Consistent data structures
- Simple JSON and/or CSV output
- Optionally email the results
- Optionally send the results to Elasticsearch, Opensearch, and/or Splunk, for use with premade dashboards
- Optionally send reports to Apache Kafka
Python Compatibility
This project supports the following Python versions, which are either actively maintained or are the default versions for RHEL or Debian.
| Version | Supported | Reason |
|---|---|---|
| < 3.6 | ❌ | End of Life (EOL) |
| 3.6 | ❌ | Used in RHEL 8, but not supported by project dependencies |
| 3.7 | ❌ | End of Life (EOL) |
| 3.8 | ❌ | End of Life (EOL) |
| 3.9 | ❌ | Used in Debian 11 and RHEL 9, but not supported by project dependencies |
| 3.10 | ✅ | Actively maintained |
| 3.11 | ✅ | Actively maintained; supported until June 2028 (Debian 12) |
| 3.12 | ✅ | Actively maintained; supported until May 2035 (RHEL 10) |
| 3.13 | ✅ | Actively maintained; supported until June 2030 (Debian 13) |
| 3.14 | ✅ | Supported (requires imapclient>=3.1.0) |