mirror of
https://github.com/domainaware/parsedmarc.git
synced 2026-07-20 15:35:01 +00:00
In the previous ASN-domain coverage sweep, the agent ran web searches for entries like `bestbuy.com → Best Buy`, `ups.com → United Parcel Service`, `usps.gov → US Postal Service`, `marriott.com → Marriott`, `henkel.cn → Henkel`, `experian.com → Experian`, `jd.com → JD.com`, `ing.com → ING`, `verisign.com → Verisign`. For each of these the domain ↔ brand pairing is encyclopedic — same outcome a few seconds slower. The two-corroborating-sources rule (rule 8) was being applied mechanically: "MMDB as_name alone is one source, must fetch a second." But for globally-known brands at their primary domain, the brand identity itself is the second source. Searching for confirmation that Best Buy owns bestbuy.com is the kind of busywork the tier system exists to avoid. Adds Tier 0 with explicit guardrails — must be globally known (multinational or top-tier-national, decades-old, single canonical entity), must be the entity's primary marketing/corporate domain (not a tracking subdomain or regional ccTLD where ownership is non-obvious), and no recent acquisition/rebrand status in question. Cross-references the existing parent-too-generic sub-rule and warns against stretching to mid-size brands the agent happens to recognize. When in doubt: drop to Tier 3 and search. Also generalizes the section's lead from "redirect-target candidates" to cover MMDB coverage-gap and PSL private-domain candidates — the tier logic transfers cleanly across all three workflows. Updates the Tier 1 description with an explicit MMDB-coverage-gap analog. Refreshes the held-back-review split stat to 0 / 109 / 2 / 34 / 35 (Tier 0 didn't apply to that batch because every candidate was a redirect target that needed to inherit the *source row's* existing canonical name, not its own brand identity). Co-authored-by: Sean Whalen <seanthegeek@users.noreply.github.com> Co-authored-by: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
parsedmarc
![]()
![]()


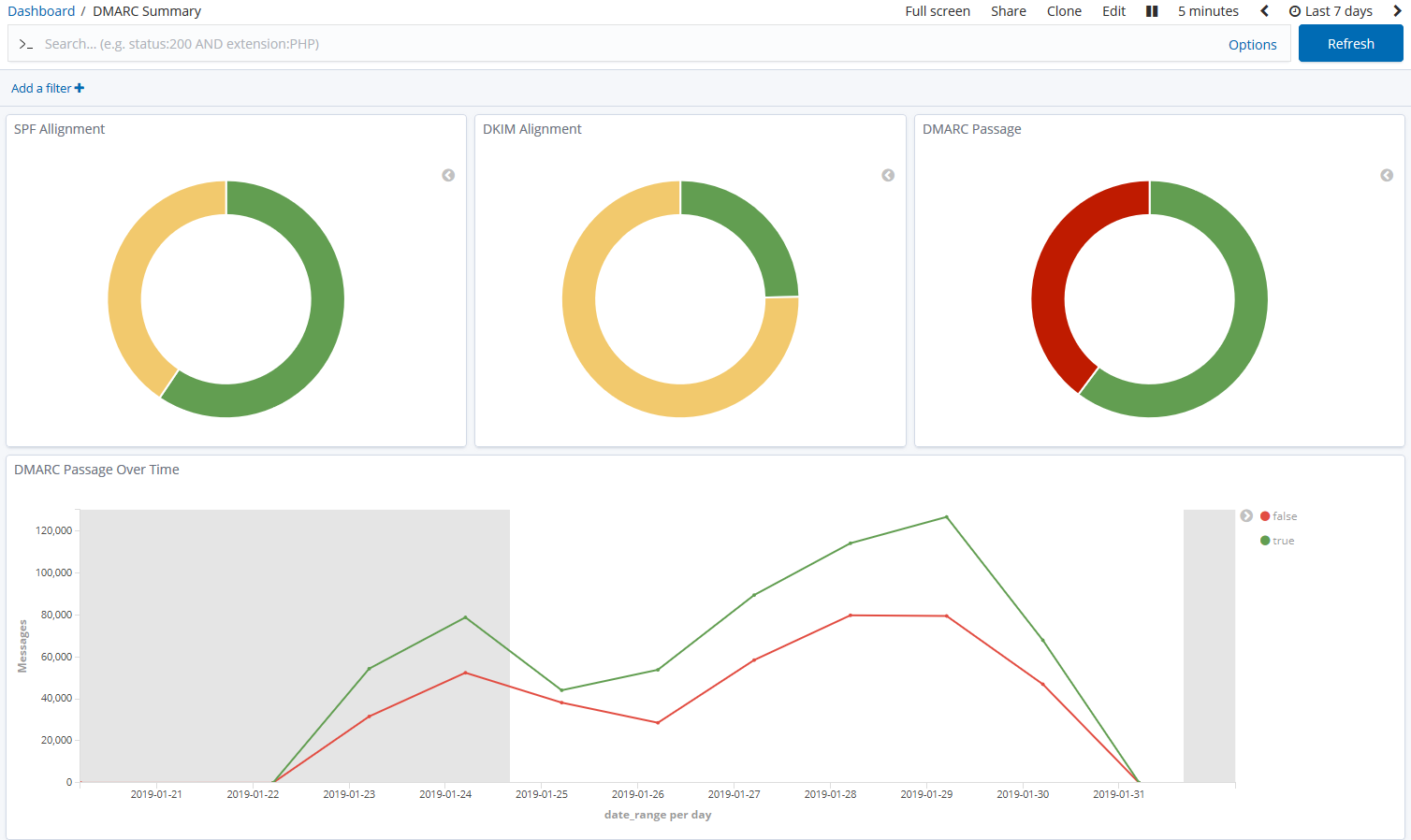
parsedmarc is a Python module and CLI utility for parsing DMARC
reports. When used with Elasticsearch and Kibana (or Splunk), it works
as a self-hosted open-source alternative to commercial DMARC report
processing services such as Agari Brand Protection, Dmarcian, OnDMARC,
ProofPoint Email Fraud Defense, and Valimail.
Note
Domain-based Message Authentication, Reporting, and Conformance (DMARC) is an email authentication protocol.
Sponsors
This is a project is maintained by one developer. Please consider sponsoring my work if you or your organization benefit from it.
Features
- Parses draft and 1.0 standard aggregate/rua DMARC reports
- Parses forensic/failure/ruf DMARC reports
- Parses reports from SMTP TLS Reporting
- Can parse reports from an inbox over IMAP, Microsoft Graph, or Gmail API
- Transparently handles gzip or zip compressed reports
- Consistent data structures
- Simple JSON and/or CSV output
- Optionally email the results
- Optionally send the results to Elasticsearch, Opensearch, and/or Splunk, for use with premade dashboards
- Optionally send reports to Apache Kafka
Python Compatibility
This project supports the following Python versions, which are either actively maintained or are the default versions for RHEL or Debian.
| Version | Supported | Reason |
|---|---|---|
| < 3.6 | ❌ | End of Life (EOL) |
| 3.6 | ❌ | Used in RHEL 8, but not supported by project dependencies |
| 3.7 | ❌ | End of Life (EOL) |
| 3.8 | ❌ | End of Life (EOL) |
| 3.9 | ❌ | Used in Debian 11 and RHEL 9, but not supported by project dependencies |
| 3.10 | ✅ | Actively maintained |
| 3.11 | ✅ | Actively maintained; supported until June 2028 (Debian 12) |
| 3.12 | ✅ | Actively maintained; supported until May 2035 (RHEL 10) |
| 3.13 | ✅ | Actively maintained; supported until June 2030 (Debian 13) |
| 3.14 | ✅ | Supported (requires imapclient>=3.1.0) |