mirror of
https://github.com/domainaware/parsedmarc.git
synced 2026-06-11 04:59:43 +00:00
When the search fallback ran on the original 6-domain smoke set, two of
the recovered titles were essentially placeholder pointers carrying no
classifier signal — DDG returned `Link to fcs.health.gov.il` for one
input and a bare `yangon.mfa.gov.il` for another. Those snippets are
DDG's way of saying "I have an indexed subdomain but no real abstract
to give you", and feeding them to the regex classifier produces no
better signal than the parking-page result we were already trying to
recover from.
This commit teaches the collector to recognize both placeholder shapes,
follow the pointer to the target hostname, and use *that* hostname's
real content for the row. The classifier then emits the original input
and the link target as **two map rows under the same (name, type)** so
both keys are looked up against future DMARC reports.
collect_domain_info.py
- New `_LINK_TO_TITLE_RE` / `_BARE_HOSTNAME_RE` and an
`_extract_link_target` helper that returns the target hostname when
the search title is `Link to <hostname>` or a bare hostname, "" when
the title carries real content.
- After the search-fallback path, if the title looks like a pointer
and the target differs from the input, `_fetch_homepage(target)` is
called once. When the target's fetch returns real (non-bot-blocked)
content, the row's title / description / final_url / rebrand_signal
/ external_links are replaced with the target's, and `title_source`
becomes `search→<target>` so reviewers can audit the path.
- New `link_target_domain` column records the followed target whether
or not its fetch succeeded.
classify_unknown_domains.py
- When a row's `link_target_domain` is set and differs from the input
domain, the classifier emits a second map row for the target with
the same `(name, type)`. The original input is the "og" domain; the
target is what DDG pointed us at — both end up in the map as
aliases. Same handling applies on the ambiguous-bucket path so a
single human adjudication covers both.
Smoke test on the original 6-domain set:
bbc.com homepage → BBC Home – Breaking News, …
1800contacts.com search → 1800contacts
health.gov.il search → Homepage – COVID Information Center
of the Israel Ministry of Health
americaneagle.com search → Americaneagle.com | Web Design …
broadwaytechnology.com search → Bloomberg Completes Acquisition of …
mfa.gov.il search→yangon.mfa.gov.il
→ Home | Ministry of Foreign Affairs
link_target_domain=yangon.mfa.gov.il
The mfa.gov.il row triggered the new path: DDG returned `yangon.mfa.gov.il`
as the title, the collector followed it, the target's homepage gave us
"Home | Ministry of Foreign Affairs", and the classifier emitted both
`mfa.gov.il, Ministry of foreign affairs, Government` and
`yangon.mfa.gov.il, Ministry of foreign affairs, Government`.
AGENTS.md updated with the link-following / alias rules under the
search-fallback subsection.
Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
parsedmarc
![]()
![]()


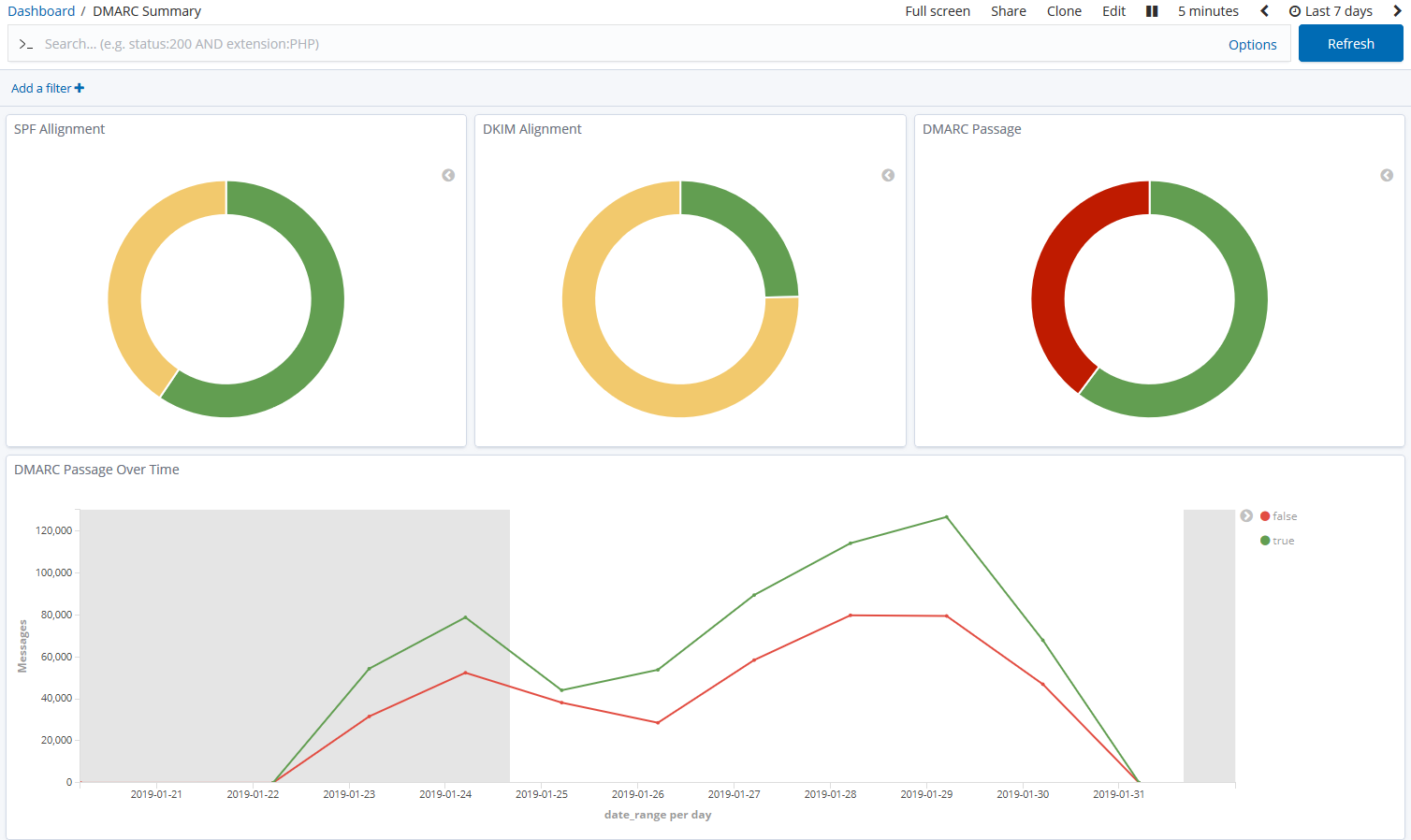
parsedmarc is a Python module and CLI utility for parsing DMARC
reports. When used with Elasticsearch and Kibana (or Splunk), it works
as a self-hosted open-source alternative to commercial DMARC report
processing services such as Agari Brand Protection, Dmarcian, OnDMARC,
ProofPoint Email Fraud Defense, and Valimail.
Note
Domain-based Message Authentication, Reporting, and Conformance (DMARC) is an email authentication protocol.
Sponsors
This is a project is maintained by one developer. Please consider sponsoring my work if you or your organization benefit from it.
Features
- Parses draft and 1.0 standard aggregate/rua DMARC reports
- Parses forensic/failure/ruf DMARC reports
- Parses reports from SMTP TLS Reporting
- Can parse reports from an inbox over IMAP, Microsoft Graph, or Gmail API
- Transparently handles gzip or zip compressed reports
- Consistent data structures
- Simple JSON and/or CSV output
- Optionally email the results
- Optionally send the results to Elasticsearch, Opensearch, and/or Splunk, for use with premade dashboards
- Optionally send reports to Apache Kafka
Python Compatibility
This project supports the following Python versions, which are either actively maintained or are the default versions for RHEL or Debian.
| Version | Supported | Reason |
|---|---|---|
| < 3.6 | ❌ | End of Life (EOL) |
| 3.6 | ❌ | Used in RHEL 8, but not supported by project dependencies |
| 3.7 | ❌ | End of Life (EOL) |
| 3.8 | ❌ | End of Life (EOL) |
| 3.9 | ❌ | Used in Debian 11 and RHEL 9, but not supported by project dependencies |
| 3.10 | ✅ | Actively maintained |
| 3.11 | ✅ | Actively maintained; supported until June 2028 (Debian 12) |
| 3.12 | ✅ | Actively maintained; supported until May 2035 (RHEL 10) |
| 3.13 | ✅ | Actively maintained; supported until June 2030 (Debian 13) |
| 3.14 | ✅ | Supported (requires imapclient>=3.1.0) |