mirror of
https://github.com/domainaware/parsedmarc.git
synced 2026-07-06 08:45:08 +00:00
* Reclassify KU pool: 2,248 promotions; surface 78 ambiguous rows for review
Re-fetched homepage / WHOIS / DNS for all 34,647 domains in
known_unknown_base_reverse_dns.txt via collect_domain_info.py and re-ran the
classifier. The classifier itself was extended in several directions while
auditing the unclassified pool — the changes are listed below.
Numbers
- 2,248 KU rows promoted to base_reverse_dns_map.csv (unambiguous matches).
- 78 rows surfaced as ambiguous (two or more distinct detector categories
fired) — these are NOT auto-promoted; they need human adjudication.
- 32,399 rows remain in KU (genuinely no signal — most have privacy-only
WHOIS, parked / blocked / Cloudflare-walled homepages, or empty MMDB
enrichment).
- Disjoint invariant verified: comm -12 of map keys and KU prints nothing.
- Unknown-list regenerated via find_unknown_base_reverse_dns.py.
Classifier changes (classify_unknown_domains.py)
1. Three output buckets via new --ambiguous-out flag. Per-row outcome is now
one of: map (auto-promote), ambiguous (worklist for human review), or
ku (no signal). When ≥2 distinct detector categories fire on a row, the
classifier picks a primary in precedence order but does NOT auto-promote
— instead it writes the row to the ambiguous TSV with the alternatives
listed. Rationale: the operator-typology question ("is this a SaaS
company or an Energy company?") is a judgment call the classifier
shouldn't make on its own.
2. Plural-matching fix: outer `\b` boundary changed to `s?\b` across all 46
detectors so `dedicated server` matches `dedicated servers`,
`law firm` matches `law firms`, etc. This was silently dropping the
majority of English-text matches.
3. TLD-only signal classification: bare-TLD rows (gov.kh / ac.id / mil.bd /
.jus.br etc.) now classify even when title/desc/as_name are all empty.
Previously short-circuited at "need some signal".
4. TLD lists massively expanded:
- Education: ~85 TLDs (every gov-restricted edu / ac suffix worldwide)
- Government: ~110 TLDs incl. judicial branch (.jus.br) and legislative
(.leg.br); covers Eastern Europe, MENA, SE Asia, Africa, Caribbean,
Pacific
- Military: ~45 .mil.* suffixes
- Plus US K-12 regex (.k12.<state>.us)
5. New concrete-vocabulary patterns added based on KU-pool audit:
- cybersecurity / cyber security for business → MSSP
- autonomous system / asn owner / network operator / peering exchange
/ IXP → ISP
- ICANN registrar / domain registrar / domain name platform / CDN /
WAF / anti-DDoS → Web Host
- BPM platform / CXM / CCaaS / CPaaS / contact center platform /
compliance software → SaaS
- katılım bankası / pensioen en verzekeringen / empréstimo consignado
/ credit (scores|reports|cards|comparison|bureau) /
stock and commodity market → Finance
- aeroportos de / passagem de ônibus / bilişim şirketi / havacılık →
Travel & Tech variants
- acciaio inossidabile / laminati piani → Industrial
- Russian football-club declension forms (футбольного клуба, etc.)
- tv channel / movie streaming / video streaming platform →
Entertainment
- genetic sequencing / next-generation sequencing /
clinical diagnostic → Healthcare
- punto vendita → Italian Retail
- electrolyser / electrolyzer / green hydrogen → Energy
6. Mojibake table extended for Western European compounds: ã/â/ê/î/ô
(Portuguese ã, French/PT â/ê/ô) plus uppercase variants.
Bug fixes from cross-language collisions
The audit pass exposed three short tokens that meant one thing in the
language they were added for and something completely different in another
language the classifier also targets:
- `por` (added as Luxembourgish for "parish" → Religion). Also the Spanish
and Portuguese preposition "for / by", which appears on roughly every
Spanish-language page. Was producing ~34 Religion false positives on
Mexican ISPs, Brazilian utilities, etc.
- `pura` (added as Indonesian/Sundanese/Balinese for "Hindu temple" →
Religion). Also the feminine of "pure" in Portuguese / Spanish / Italian,
and a frequent brand-name fragment ("Pura Energia", "Angkasa Pura").
Was misclassifying Brazilian electric utilities and Indonesian aviation
services.
- bare `broker` (added as Luxembourgish for Finance). Matched any English
text containing "broker" / "brokers" — including Cushman & Wakefield's
"real estate brokers" line, which forced the row into Finance instead
of Real Estate.
All three removed; AGENTS.md now codifies the rule.
AGENTS.md additions
- "Three output buckets" subsection: documents map / ambiguous / ku output
and how PRs should call out ambiguous review counts.
- "No taglines / slogans" rule: marketing copy ("we make it easy",
"smarter decisions") doesn't belong in any detector.
- "No ambiguous signals" rule: cross-category bare words (gazette / academy
/ society / club / studio) are forbidden as classifier keywords; use the
pinning compound instead. Same rule applies in every language.
- "Cross-language grammar / lexical overlap" rule: short tokens that mean X
in language A often mean a function word / adjective / brand fragment in
language B. Cites the por / pura / broker incidents.
- "Classify by what the operator literally provides" rule: clusters by
acronym suffix (UCaaS / CCaaS / CPaaS) tempt mis-grouping; CCaaS is SaaS
not ISP, etc. Includes the root-cause analysis of the
contact-center-as-ISP mistake.
- "Genuinely-ambiguous-between-two-types" rule: phrases like
"energy management software" that fit equally on a SaaS startup, an
Industrial conglomerate, and a consultancy belong in NO detector — leave
the row unmapped and rely on more-specific compounds.
Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
* Triage 78 ambiguous rows + new classifier filters and rules
Interactive triage of the 78 rows the v1 classifier surfaced as ambiguous
(two or more distinct categories fired). Net result of this commit, on
top of the v1 promotions already in the branch:
- 74 ambiguous rows promoted to map with a human-adjudicated category
(and 10 of those with a corrected human-cleaned brand vs. the noisy
as_name / title-bleed the v1 classifier captured).
- 1 row dropped silently per the AGENTS.md adult-content rule.
- 3 rows kept in KU (personal projects, parked pages caught by the
classifier mid-triage that we then surface'd-then-confirmed).
Map: 37,566 → 37,640 (+74). KU: 32,399 → 32,324 (−75). Disjoint clean.
Three new classifier filters added during triage as recurring patterns
surfaced — these run before category detectors and short-circuit to KU
or DROP rather than letting the operator-typology detectors fire on
parking-page / personal-page / adult-page text:
1. PARKED_PAGE_RE — Media Temple "automatically generated default server
page", Hostinger Horizons, Apache default, parked-by-registrar pages,
"site has shut down", "has completed its journey". Cloudflare /
DDoS-Guard / "Are you a robot?" interstitials are explicitly NOT
filtered (they leave the TLD-signal path open for gov / edu / mil
sites that are bot-blocked).
2. PERSONAL_PROJECT_RE — "personal BGP project", "personal website and
CV", "homelab", "hobby project", "side project". Hobbyists running
their own ASN aren't commercial operators.
3. ADULT_CONTENT_RE — adult web design / adult-entertainment hosting /
xxx / escort directory etc. Returns a sentinel ("DROP", None) so the
caller drops the domain from both map and KU per the AGENTS.md
content rule.
The classifier API now also writes a fourth output file (--dropped-out)
listing domains the adult-content filter caught, so the caller can
remove them from any tracked list files they currently sit in.
Title-noise list extended to catch: "attention required" / "are you a
robot" / "checking your browser" / "please enable javascript" /
"ddos-guard" / "px-captcha" / "site is not available" / "page is not
available" / "access to this page has been denied". This stops these
strings from bleeding into the brand column when TLD-only classification
fires (the `health.gov.il → "Attention Required!"` shape of bug).
Several cross-language false positives caught during the triage — same
shape as the por / pura / broker incidents the previous commit fixed:
- bare French `e?mailing` matched "Mailing Solutions" (mail-server
infrastructure on a Cisco VAR's product list, not marketing). Required
to start with `e` to keep the email-marketing meaning while losing the
bare-mailing collision.
- Norwegian / Danish bare `avis` (newspaper) matched "Avis Romania" car
rental and any French text saying "avis" (notice/opinion). Replaced
with compound forms (`dagsavis`, `lokalavis`, `morgenavis`, etc.).
- Vietnamese bare `bộ` (ministry) matched "bộ phim" (movie set), "bộ
sưu tập" (collection), and the founding-text references on Vietnam
Eximbank's about page. Replaced with compound forms (`bộ trưởng`, `bộ
tài chính`, `bộ ngoại giao`, etc.).
- Russian bare `провайдер` (provider) matched "хостинг провайдер"
(hosting provider, Web Host) on a Tajikistan domain registrar. Removed
the bare form; only the internet-specific compounds remain.
- Luxembourgish bare `broker` (Finance) matched "real estate brokers"
on Cushman & Wakefield's homepage and any English page mentioning
brokers. Removed the bare form entirely.
- Turkish bare `vakıf` (foundation) matched "Vakıf Katılım Bankası" —
for-profit Islamic-finance bank whose brand uses the word. Replaced
with nonprofit-specific compounds (`yardım vakfı`, `hayır vakfı`,
`kamu yararına vakıf`).
New positive-classification keywords added based on triage gaps:
- MSP rescue path now matches the SMB-IT-shop idiom in Polish
(`usługi IT dla biznesu`, `obsługa informatyczna firm`,
`outsourcing IT`), Spanish (`servicios informáticos para empresas`),
German (`IT-Dienstleister für`, `managed-IT-services`), French
(`infogérance`, `prestataire de services informatiques`), Italian
(`servizi informatici gestiti`, `outsourcing informatico`),
Portuguese (`serviços de TI gerenciados`, `terceirização de TI`),
Dutch (`beheerd-IT`, `IT-beheer`), and Indonesian
(`penyedia solusi IT`, `solusi IT terpadu/berbasis`).
- Finance now matches `accounting firm` / `cpa firm` /
`certified public accountants` / `chartered accountants` /
`tax preparation` / `tax advisory` / `audit firm` plus equivalents in
Spanish, Portuguese, French, German, Italian, and Polish.
- SaaS now matches CCaaS / CPaaS / `contact-center-as-a-service` /
`communications-platform-as-a-service` / `compliance software` /
`regulatory management software` and CCaaS no longer lives in ISP
(carryover from the user-flagged "contact centers are not ISPs"
correction).
AGENTS.md additions:
- "Triage heuristics learned from the 78-row interactive review of
PR #766's ambiguous bucket" subsection codifying every adjudication
rule the user applied during the review:
* pick the main-focus category (first / most-mentioned)
* clients are not operator typology
* vertically-specialized firms take the vertical
* stream-hosting infrastructure is Web Host
* multi-service SMB IT shops are MSP
* VARs are Technology
* CCaaS / CPaaS / UCaaS are SaaS
* gov/edu/mil/jus TLD signal trumps Cloudflare interstitials
* esports tournament organizers are Entertainment
* personal projects / parked pages / adult content go to KU or DROP
* brand quality is its own dimension — capture corrected brand
during triage rather than shipping the noisy as_name
Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
---------
Co-authored-by: Sean Whalen <seanthegeek@users.noreply.github.com>
Co-authored-by: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
parsedmarc
![]()
![]()


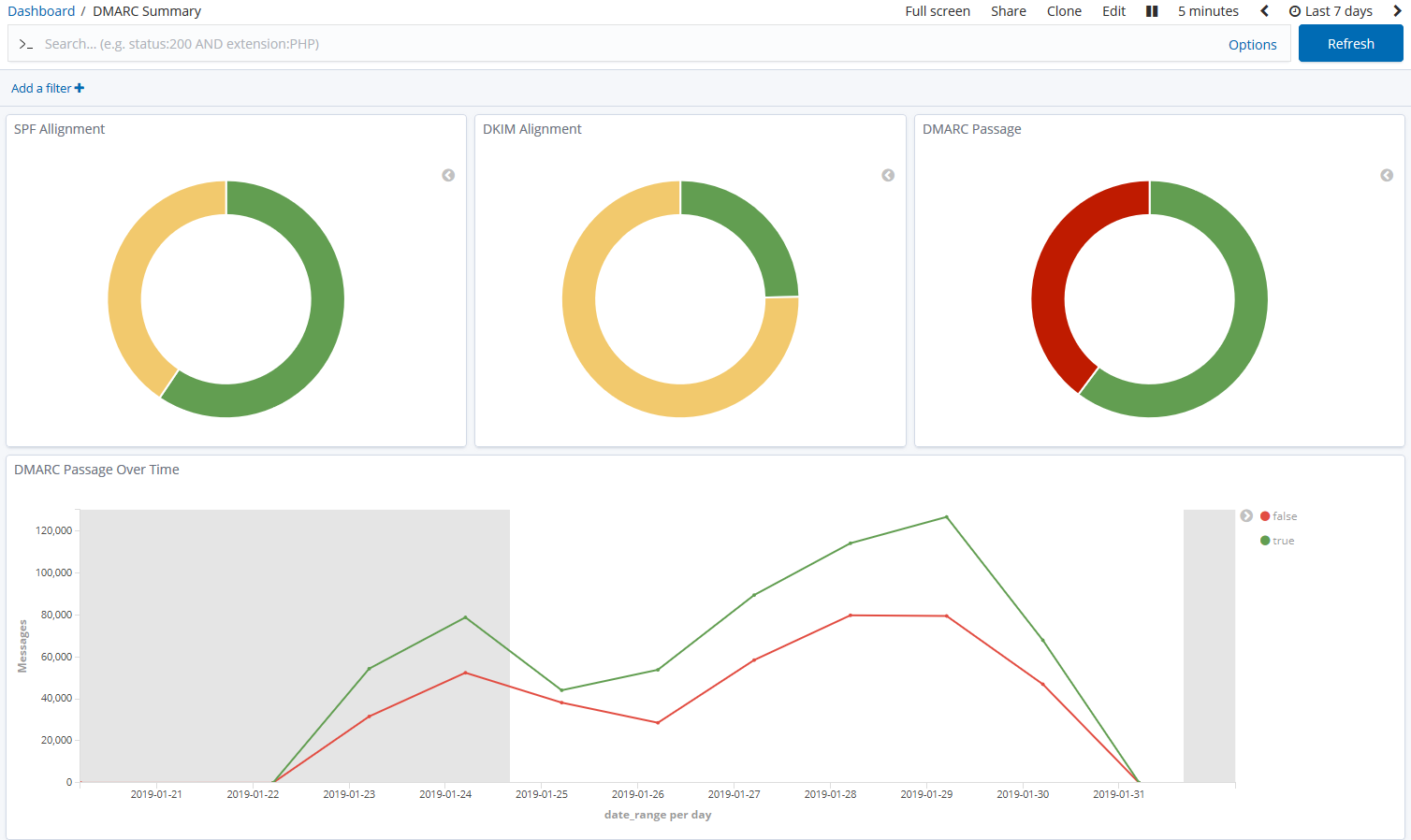
parsedmarc is a Python module and CLI utility for parsing DMARC
reports. When used with Elasticsearch and Kibana (or Splunk), it works
as a self-hosted open-source alternative to commercial DMARC report
processing services such as Agari Brand Protection, Dmarcian, OnDMARC,
ProofPoint Email Fraud Defense, and Valimail.
Note
Domain-based Message Authentication, Reporting, and Conformance (DMARC) is an email authentication protocol.
Sponsors
This is a project is maintained by one developer. Please consider sponsoring my work if you or your organization benefit from it.
Features
- Parses draft and 1.0 standard aggregate/rua DMARC reports
- Parses forensic/failure/ruf DMARC reports
- Parses reports from SMTP TLS Reporting
- Can parse reports from an inbox over IMAP, Microsoft Graph, or Gmail API
- Transparently handles gzip or zip compressed reports
- Consistent data structures
- Simple JSON and/or CSV output
- Optionally email the results
- Optionally send the results to Elasticsearch, Opensearch, and/or Splunk, for use with premade dashboards
- Optionally send reports to Apache Kafka
Python Compatibility
This project supports the following Python versions, which are either actively maintained or are the default versions for RHEL or Debian.
| Version | Supported | Reason |
|---|---|---|
| < 3.6 | ❌ | End of Life (EOL) |
| 3.6 | ❌ | Used in RHEL 8, but not supported by project dependencies |
| 3.7 | ❌ | End of Life (EOL) |
| 3.8 | ❌ | End of Life (EOL) |
| 3.9 | ❌ | Used in Debian 11 and RHEL 9, but not supported by project dependencies |
| 3.10 | ✅ | Actively maintained |
| 3.11 | ✅ | Actively maintained; supported until June 2028 (Debian 12) |
| 3.12 | ✅ | Actively maintained; supported until May 2035 (RHEL 10) |
| 3.13 | ✅ | Actively maintained; supported until June 2030 (Debian 13) |
| 3.14 | ✅ | Supported (requires imapclient>=3.1.0) |