mirror of
https://github.com/domainaware/parsedmarc.git
synced 2026-07-05 16:25:09 +00:00
* Explain why a report is invalid instead of "Not a valid report"
The parser catches broadly so one malformed report can't crash a batch,
but every failure surfaced as the generic ParserError("Not a valid
report"), telling operators nothing about the cause.
parse_report_file() now keeps each format parser's specific error as it
tries aggregate XML -> SMTP TLS JSON -> report email, and when all three
reject the input it content-sniffs the leading byte to surface the single
relevant reason (e.g. "Invalid aggregate report: Missing field:
'org_name'", or "Not a recognized report format (...)"). The CLI already
logs str(error), so this reaches the user with no cli.py change.
Every parser catch site also re-raises with `raise ... from <original>`,
preserving the underlying ExpatError / JSONDecodeError / KeyError /
archive errors on __cause__ for library callers and tracebacks. The same
exception *types* are still raised.
Finally, the catch-all "unexpected error" branches append
`(raised at <file>:<line>)` from the deepest traceback frame, but only
when the parsedmarc logger is at DEBUG level (e.g. the CLI's --debug);
normal-level output is unchanged.
Bumps the in-progress version to 10.2.0 and documents all three in the
CHANGELOG.
Co-Authored-By: Claude Opus 4.8 (1M context) <noreply@anthropic.com>
* Cover the failure-report path in parse_report_file error tests
The reason-surfacing tests covered the aggregate and SMTP TLS branches but
not failure reports, which reach parse_report_file only via the email
path. Add a malformed multipart/report failure email (missing the required
Source-IP) and assert the message names the failure format and the missing
field rather than collapsing to "Not a valid report".
Co-Authored-By: Claude Opus 4.8 (1M context) <noreply@anthropic.com>
* Cover the new error-reporting lines; drop one unreachable catch
Bring the lines added by this PR to full test coverage:
- Test _exc_origin() with a never-raised exception (no __traceback__) so the
"no frames" guard is exercised.
- Test _parse_smtp_tls_failure_details() with a non-dict, which raises
TypeError (not KeyError) and exercises the generic catch-all.
- Test parse_report_email() with an unparseable Date header, which trips the
initial mail-parse catch-all and becomes a ParserError.
Two dead lines are removed rather than hidden, per the project's "delete
unreachable branches, no # pragma: no cover" rule:
- _looks_like_email() looped with a `continue` for blank lines, but every
caller passes lstrip()-ed text, so the first line is never blank. Simplified
to inspect the first line directly.
- parse_report_email()'s `except Exception` after `except InvalidFailureReport`
was unreachable: parse_failure_report wraps its entire body and provably
raises only InvalidFailureReport, which the preceding handler already catches.
Co-Authored-By: Claude Opus 4.8 (1M context) <noreply@anthropic.com>
* Fix IndexError when backfilling envelope_from from SPF results
_parse_report_record() backfills a missing/empty envelope_from from the
last SPF auth result's domain. The "envelope_from is None" branch gated on
the raw auth_results["spf"] list but indexed the filtered
new_record["auth_results"]["spf"] list, which only holds results that have
a domain. A reporter sending an SPF result with no domain made the filtered
list empty while the raw list was non-empty, so [-1] raised IndexError and
the whole record failed to parse.
The two near-identical envelope_from backfill branches (missing identifier
vs. empty identifier) drifted apart -- only one was updated when the
filtered new_record list was introduced -- which is what let them disagree
on which list to read. Merge them into a single path, keyed on
dict.get("envelope_from") is None, that gates and indexes the same raw list
with the "domain" membership guard the missing-identifier branch already
used.
Regression test: envelope_from=None with an SPF result carrying no domain
now parses to envelope_from=None instead of raising. This is the bug that
motivated the surrounding error-reporting work in this PR.
Co-Authored-By: Claude Opus 4.8 (1M context) <noreply@anthropic.com>
* Trim comment
* Cover the touched error branches; drop a dead UnicodeDecodeError catch
Codecov flagged the pre-existing error branches this PR touched (adding
`from e` / `_exc_origin`) as changed-and-uncovered. Most are real
malformed-report paths, so add honest tests that drive them with realistic
inputs:
- parse_smtp_tls_report_json: nested missing key (date-range without
start-datetime) -> InvalidSMTPTLSReport chaining a KeyError.
- parse_aggregate_report_xml: non-structured report_metadata -> the
AttributeError branch ("Report missing required section").
- parse_report_email: valid legacy text/plain failure report (success path),
a text report missing its fields, a base64 attachment of malformed
aggregate XML, and one of invalid SMTP TLS JSON.
- parse_report_file: gzipped junk -> the str branch of the content sniff.
The `except UnicodeDecodeError` in extract_report is removed as dead code
(no `# pragma: no cover`, per the repo rule): str-mode streams are already
rejected by explicit isinstance checks, and every decode() uses
errors="ignore", so it can never fire. str-mode still raises ParserError.
Also rename the two new failure-report tests from "Forensic" to "Failure"
and add an AGENTS.md rule: RUF reports are "failure reports"; "forensic" is
reserved for the literal backward-compat alias identifiers only.
Co-Authored-By: Claude Opus 4.8 (1M context) <noreply@anthropic.com>
* Fix pyright errors in the new error-branch tests
CI runs pyright over the whole repo (tests included); these slipped through
because the local check only covered parsedmarc/__init__.py:
- _parse_smtp_tls_failure_details("not a dict") is a deliberate wrong-type
test -> targeted `# pyright: ignore[reportArgumentType]`.
- result["report"]["source"]["ip_address"] on a ParsedReport TypedDict ->
cast(FailureReport, result["report"]) first, matching existing tests.
This is what failed lint-docs-build (and, since `test` needs it, skipped the
Codecov upload) on the prior commits.
Co-Authored-By: Claude Opus 4.8 (1M context) <noreply@anthropic.com>
---------
Co-authored-by: Claude Opus 4.8 (1M context) <noreply@anthropic.com>
parsedmarc
![]()
![]()


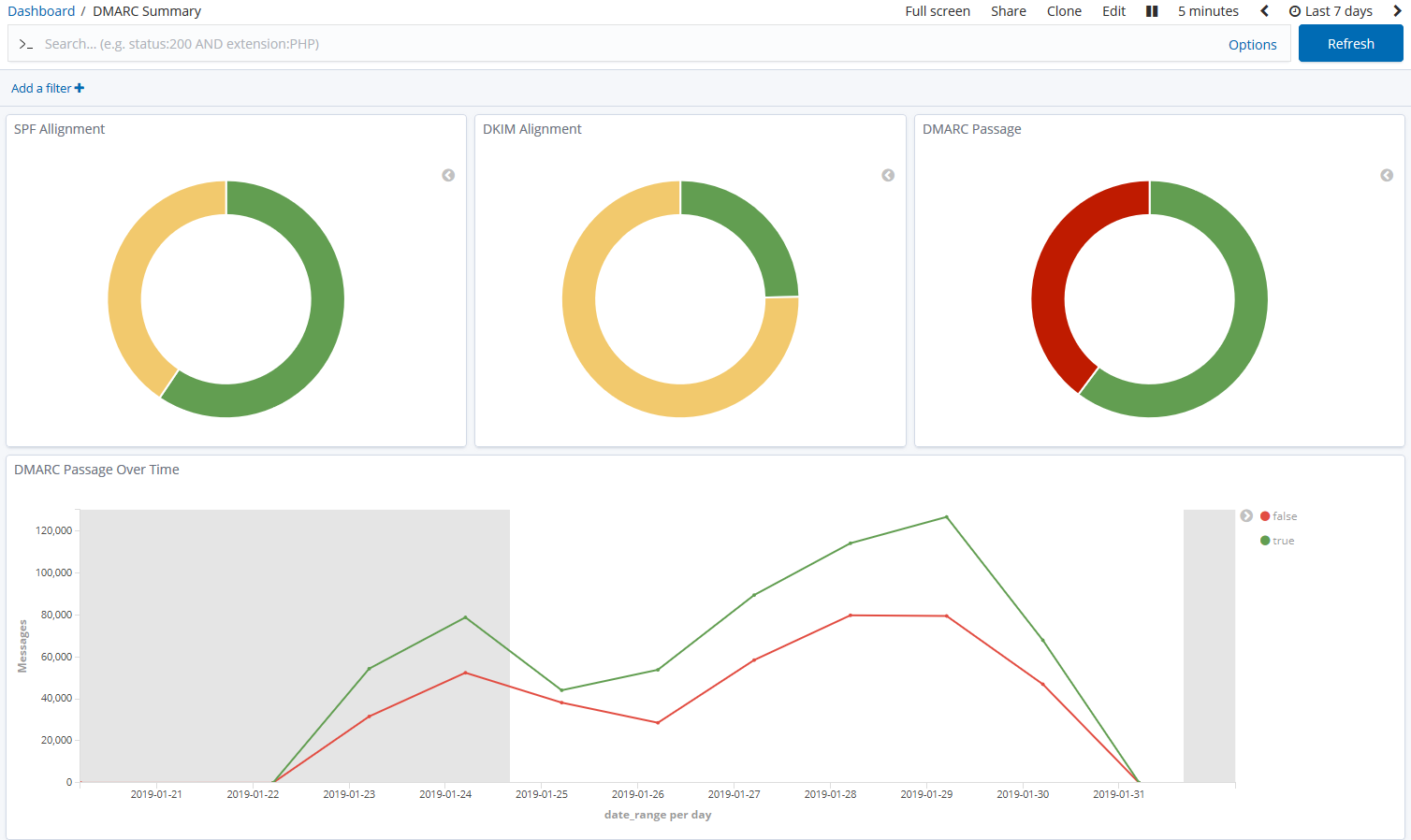
parsedmarc is a Python module and CLI utility for parsing DMARC
reports. When used with Elasticsearch and Kibana (or Splunk), it works
as a self-hosted open-source alternative to commercial DMARC report
processing services such as Agari Brand Protection, Dmarcian, OnDMARC,
ProofPoint Email Fraud Defense, and Valimail.
Note
Domain-based Message Authentication, Reporting, and Conformance (DMARC) is an email authentication protocol.
Sponsors
This is a project is maintained by one developer. Please consider sponsoring my work if you or your organization benefit from it.
Features
- Parses aggregate/rua DMARC reports: the legacy draft and 1.0 schemas (RFC 7489) and the new RFC 9990 schema for the final DMARC standard (RFC 9989)
- Parses failure/ruf DMARC reports (RFC 6591 and RFC 9991; formerly called forensic reports)
- Parses reports from SMTP TLS Reporting (TLS-RPT, RFC 8460)
- Can parse reports from an inbox over IMAP, Microsoft Graph, or Gmail API
- Transparently handles gzip or zip compressed reports
- Consistent data structures
- Simple JSON and/or CSV output
- Optionally email the results
- Optionally send the results to Elasticsearch, OpenSearch, Splunk, or PostgreSQL, for use with premade dashboards
- Optionally send the results to Apache Kafka, Amazon S3, Azure Log Analytics (Microsoft Sentinel), a Graylog (GELF) endpoint, a syslog server, or an HTTP webhook
Python Compatibility
This project supports the following Python versions, which are either actively maintained or are the default versions for RHEL or Debian.
| Version | Supported | Reason |
|---|---|---|
| < 3.6 | ❌ | End of Life (EOL) |
| 3.6 | ❌ | Used in RHEL 8, but not supported by project dependencies |
| 3.7 | ❌ | End of Life (EOL) |
| 3.8 | ❌ | End of Life (EOL) |
| 3.9 | ❌ | Used in Debian 11 and RHEL 9, but not supported by project dependencies |
| 3.10 | ✅ | Actively maintained |
| 3.11 | ✅ | Actively maintained; supported until June 2028 (Debian 12) |
| 3.12 | ✅ | Actively maintained; supported until May 2035 (RHEL 10) |
| 3.13 | ✅ | Actively maintained; supported until June 2030 (Debian 13) |
| 3.14 | ✅ | Supported (requires imapclient>=3.1.0) |