mirror of
https://github.com/domainaware/parsedmarc.git
synced 2026-07-06 00:35:09 +00:00
5x the typical batch size to chase complete ASN-domain coverage. Small ISPs and web hosts are high-value targets for spam/phishing abuse, so the long tail of unmapped operators is worth investing review effort in. Each candidate at this depth represents 3,072–6,144 IPv4 addresses (well below the 100K+ that head-batches saw); auto-classification rate is 43.5%, similar to the prior batch. - 2,177 added to base_reverse_dns_map.csv (ISP 1,477, Web Host 296, Education 214, MSP 65, Government 56, Healthcare 40, Finance 29). - 2,823 added to known_unknown_base_reverse_dns.txt — parked / Cloudflare- challenged / generic-server-test pages, obscure-language homepages without telecom-keyword cognates the classifier recognized, or rows whose WHOIS / MMDB as_name / homepage couldn't combine into two corroborating sources. ASN-domain coverage of the bundled IPinfo Lite MMDB after this batch: - by domain count: 12,678 / 63,993 (19.81%, up from 15.86%) - by IPv4 weight: 97.85% (up from 97.55%) Reused the batch-5 classifier (MMDB as_name as primary brand source with domain-root-aware title-segment selection, multilingual ISP/Web Host/MSP keyword regex, government and education TLD lists, Communications-with- media-context-guard fallback, and the deep brand-suffix cleanup for EPP/EIRELI/UAB/Druzstvo/etc. plus the UTF-8-as-Latin-1 mojibake fix). No new classifier changes this batch. Co-authored-by: Sean Whalen <seanthegeek@users.noreply.github.com> Co-authored-by: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
parsedmarc
![]()
![]()


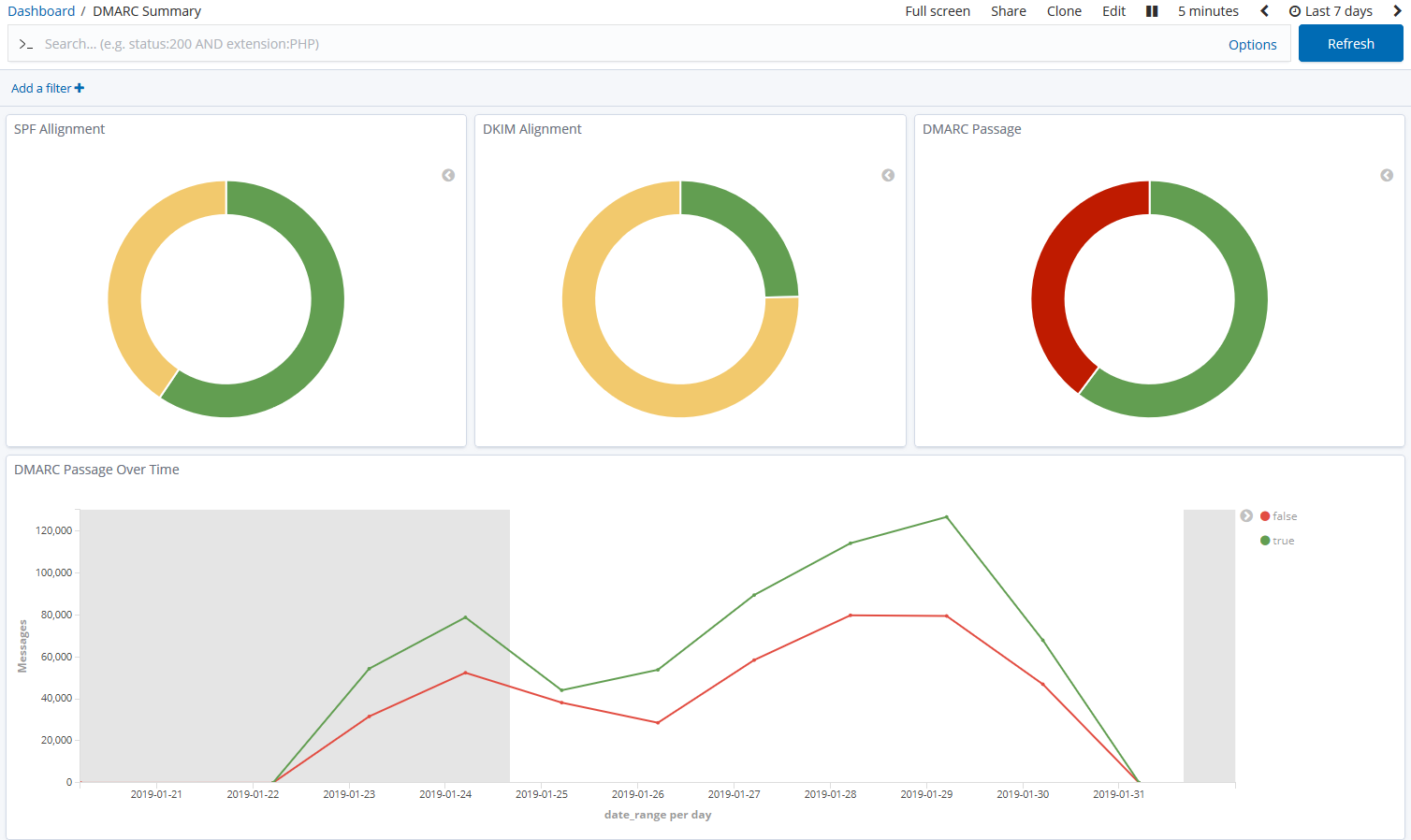
parsedmarc is a Python module and CLI utility for parsing DMARC
reports. When used with Elasticsearch and Kibana (or Splunk), it works
as a self-hosted open-source alternative to commercial DMARC report
processing services such as Agari Brand Protection, Dmarcian, OnDMARC,
ProofPoint Email Fraud Defense, and Valimail.
Note
Domain-based Message Authentication, Reporting, and Conformance (DMARC) is an email authentication protocol.
Sponsors
This is a project is maintained by one developer. Please consider sponsoring my work if you or your organization benefit from it.
Features
- Parses draft and 1.0 standard aggregate/rua DMARC reports
- Parses forensic/failure/ruf DMARC reports
- Parses reports from SMTP TLS Reporting
- Can parse reports from an inbox over IMAP, Microsoft Graph, or Gmail API
- Transparently handles gzip or zip compressed reports
- Consistent data structures
- Simple JSON and/or CSV output
- Optionally email the results
- Optionally send the results to Elasticsearch, Opensearch, and/or Splunk, for use with premade dashboards
- Optionally send reports to Apache Kafka
Python Compatibility
This project supports the following Python versions, which are either actively maintained or are the default versions for RHEL or Debian.
| Version | Supported | Reason |
|---|---|---|
| < 3.6 | ❌ | End of Life (EOL) |
| 3.6 | ❌ | Used in RHEL 8, but not supported by project dependencies |
| 3.7 | ❌ | End of Life (EOL) |
| 3.8 | ❌ | End of Life (EOL) |
| 3.9 | ❌ | Used in Debian 11 and RHEL 9, but not supported by project dependencies |
| 3.10 | ✅ | Actively maintained |
| 3.11 | ✅ | Actively maintained; supported until June 2028 (Debian 12) |
| 3.12 | ✅ | Actively maintained; supported until May 2035 (RHEL 10) |
| 3.13 | ✅ | Actively maintained; supported until June 2030 (Debian 13) |
| 3.14 | ✅ | Supported (requires imapclient>=3.1.0) |