mirror of
https://github.com/domainaware/parsedmarc.git
synced 2026-07-06 00:35:09 +00:00
* Tighten rebrand regex to drop CTA, third-party-mention, and CSS-asset FPs The first run of detect_rebrands.py against the live map surfaced systemic false-positive categories that drowned the real signals. Tightening over two rounds of FP triage: REBRAND_RE — drop bare "now <Cap>" and "joined the X" branches: - "Buy Now PROMO", "Apply Now Who", "Order Now Free Shipping" — modern marketing pages saturate body text with CTA fragments and ~95% of bare "now <Capital>" matches were these. Replaced with the linguistically meaningful pattern "(is|are|was|were|am) now (?:(?:a )?part of)?" which still catches "BankOnIT is now Navanta", "We are now Cencora", "is now part of Lumen", etc. - "joined the Festo Certified System Integrator Program", "joined the ClimateCAP Initiative", "joined the Fredonia Women's Rugby team" — the "joined the X" pattern was too generic; real "joined the X family" rebrand banners are rare enough that dropping the branch is the right trade. REBRAND_RE — add `\b` word boundary at the start so triggers don't match mid-word: "Stre*am* now Mystery" was matching `am now <Cap>` because the last two letters of "Stream" satisfied the verb alternation. REBRAND_PATH_RE — drop bare `rebrand`, `name change`, `new name for`, and `brand-update` / `brand-refresh` patterns. They appeared too often as CSS class names (`class="rebrand-page"`), CSS variables (`--rebrand-underline-color`), image filenames (`bms-rebrand-logo.svg`, `brand-update.css`), and JSON/JS strings (`"name change"` user-account labels). Adding `\b` boundaries doesn't help because dashes are non-word characters. The remaining narrow patterns (`brand-launch`, `brand-announcement`, `brand-reveal`, `our-new-name`, `our-new-brand`, `acquisition-announcement`, `merger-announcement`) still catch the canonical bankonitusa.com case via its `brand-launch-frequently-asked- questions` URL slug and `Brand announcement` alt text. _REBRAND_NOISE — make the comparison case-insensitive and add "included", "iso", "secure", "part" to suppress "is now ON" / "is now LIVE" / "is now ISO 27001 certified" / "is now Secure Managed Wi-Fi" / "is now Part of" patterns. Twitter/Facebook/Square (the social-platform rebrand mentions in footers like "X (formerly Twitter)") moved to lowercase since the comparison is now case-insensitive. Net effect on a full sweep over the ~13,100-key map: rebrand-signal flagged-row count dropped from ~270 (initial run) to 108 (round-3), clearing the dominant FP categories while every real signal — verified against the bankonitusa.com canonical case plus 11 other actual rebrands — still fires. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com> * Promote 11 verified rebrands found by drift sweep; alias 4 acquirer domains Renames produced by `detect_rebrands.py` running against the full ~13,100-key map and verified by re-reading each operator's homepage. Type column unchanged for every row — only the canonical `name` shifts to the new operator. Where the new operator's primary domain wasn't already in the map, a case-1 alias row is added pointing to the same `(name, type)`. Renames: - amerisourcebergen.com: AMERISOURCEBERGEN → Cencora - aurorahealthcare.org: Aurora Health Care → Advocate Health - consolidated.com: Consolidated Communications → Fidium Fiber - databridgesites.com: Meridian Parkway Data Center Owner → TierPoint - emarsys.com: SAP Emarsys → SAP Engagement Cloud - rig.net: RigNet → Viasat - rxlightning.com: RxLightning → CoverMyMeds - telepoint.bg: Telepoint → Digital Realty - thehostgroup.com: The Host Group → HostGo - ultisat.com: Globecomm Services Maryland → UltiSat - unifiedpostgroup.com: Unifiedpost Group → Banqup New aliases (operator's primary domain not previously mapped): - cencora.com → Cencora, Healthcare - advocatehealth.com → Advocate Health, Healthcare - covermymeds.com → CoverMyMeds, Healthcare - banqup.com → Banqup, SaaS Five sweep hits intentionally deferred for lack of a clear second source: megatel.co.nz → Nova (`nova.co.nz` is for sale via a domain broker; unclear which Nova entity), pogozone.com → NeuBeam (NeuBeam's homepage doesn't acknowledge the PogoZone acquisition), prempub.com → Ingenious Media (ingeniousmedia.com fetch failed), voltagepark.com → ? (merger with Lightning AI rather than a clean rebrand), and a handful of more ambiguous Synopsys/Ansys/OmniAccess/Rakuten/Indigital/Synthite signals that need manual research. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com> * Document detect_rebrands.py cadence as run-once-a-year The drift sweep is for catching operator rebrands and acquisitions that accumulated since the previous run; M&A activity over the mapped operator set is slow enough that yearly is sufficient. Annotate the script's own docstring, the maps README, and the AGENTS.md "Related utility scripts" entry so a future contributor doesn't mistake it for a per-batch step. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com> --------- Co-authored-by: Sean Whalen <seanthegeek@users.noreply.github.com> Co-authored-by: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
parsedmarc
![]()
![]()


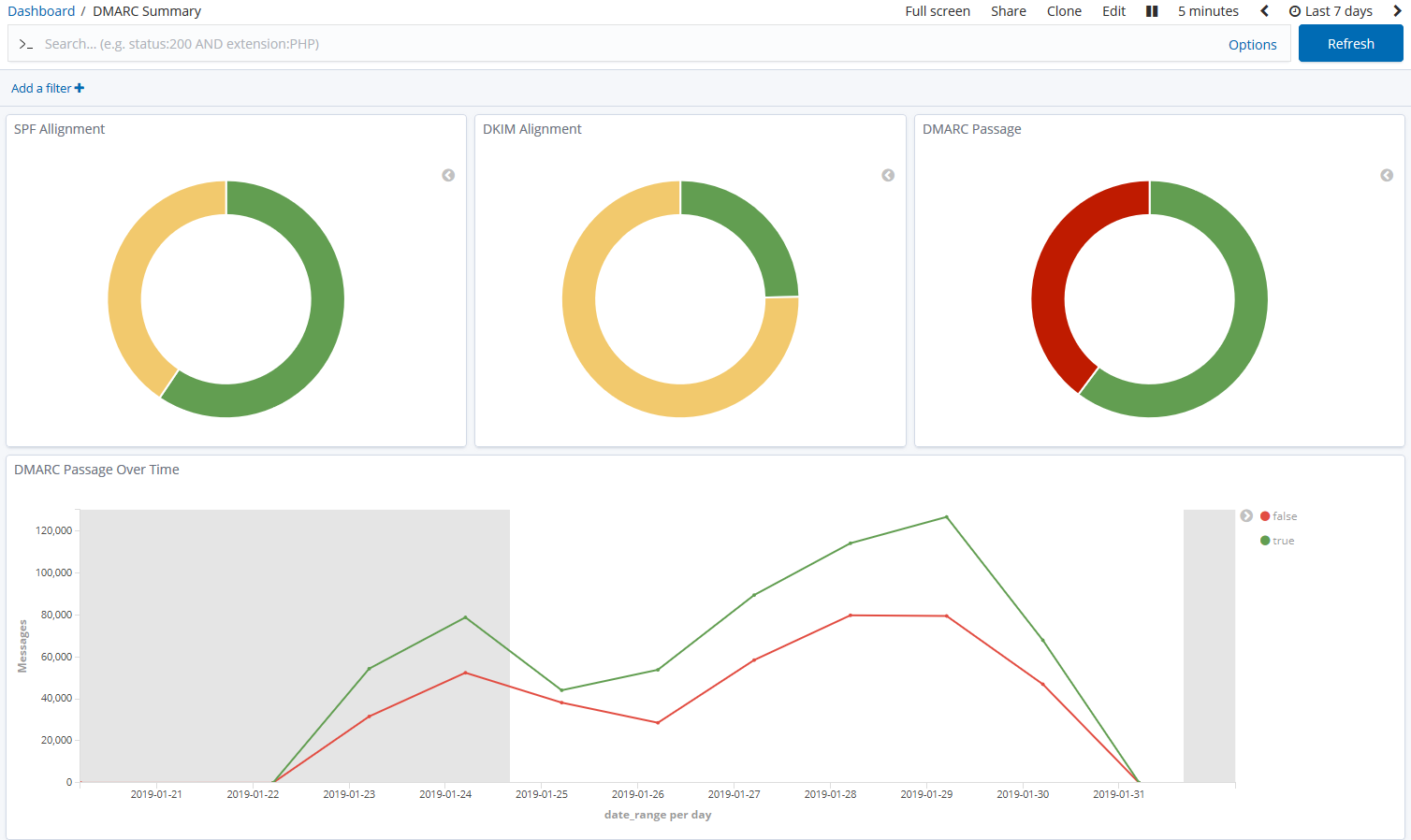
parsedmarc is a Python module and CLI utility for parsing DMARC
reports. When used with Elasticsearch and Kibana (or Splunk), it works
as a self-hosted open-source alternative to commercial DMARC report
processing services such as Agari Brand Protection, Dmarcian, OnDMARC,
ProofPoint Email Fraud Defense, and Valimail.
Note
Domain-based Message Authentication, Reporting, and Conformance (DMARC) is an email authentication protocol.
Sponsors
This is a project is maintained by one developer. Please consider sponsoring my work if you or your organization benefit from it.
Features
- Parses draft and 1.0 standard aggregate/rua DMARC reports
- Parses forensic/failure/ruf DMARC reports
- Parses reports from SMTP TLS Reporting
- Can parse reports from an inbox over IMAP, Microsoft Graph, or Gmail API
- Transparently handles gzip or zip compressed reports
- Consistent data structures
- Simple JSON and/or CSV output
- Optionally email the results
- Optionally send the results to Elasticsearch, Opensearch, and/or Splunk, for use with premade dashboards
- Optionally send reports to Apache Kafka
Python Compatibility
This project supports the following Python versions, which are either actively maintained or are the default versions for RHEL or Debian.
| Version | Supported | Reason |
|---|---|---|
| < 3.6 | ❌ | End of Life (EOL) |
| 3.6 | ❌ | Used in RHEL 8, but not supported by project dependencies |
| 3.7 | ❌ | End of Life (EOL) |
| 3.8 | ❌ | End of Life (EOL) |
| 3.9 | ❌ | Used in Debian 11 and RHEL 9, but not supported by project dependencies |
| 3.10 | ✅ | Actively maintained |
| 3.11 | ✅ | Actively maintained; supported until June 2028 (Debian 12) |
| 3.12 | ✅ | Actively maintained; supported until May 2035 (RHEL 10) |
| 3.13 | ✅ | Actively maintained; supported until June 2030 (Debian 13) |
| 3.14 | ✅ | Supported (requires imapclient>=3.1.0) |