mirror of
https://github.com/domainaware/parsedmarc.git
synced 2026-07-05 16:25:09 +00:00
* Split tests.py into per-module tests/test_<module>.py The 5174-line tests.py monolith is split into per-module files under tests/, mirroring the checkdmarc layout: tests/test_init.py parsedmarc/__init__.py parsing surface tests/test_cli.py parsedmarc/cli.py + config / env-vars / SIGHUP tests/test_utils.py parsedmarc/utils.py (DNS, IP info, PSL, etc.) tests/test_webhook.py parsedmarc/webhook.py tests/test_kafkaclient.py parsedmarc/kafkaclient.py tests/test_splunk.py parsedmarc/splunk.py tests/test_syslog.py parsedmarc/syslog.py tests/test_loganalytics.py parsedmarc/loganalytics.py tests/test_gelf.py parsedmarc/gelf.py tests/test_s3.py parsedmarc/s3.py tests/test_maps.py parsedmarc/resources/maps/ maintainer scripts The split is purely a redistribution — no test bodies changed, no tests added or removed. All 276 existing tests pass under the new layout. The current tests.py contains two kitchen-sink classes (`Test` at line 54 and `TestEnvVarConfig` at line 2360) holding tests that span many modules. Their methods are routed to the correct per-module file by name prefix; the wholly-thematic classes (TestExtractReport, TestUtilsXxx, TestSighupReload, etc.) move whole. Each target file gets its own `class Test(unittest.TestCase)` for the redistributed kitchen-sink methods, plus the thematic classes verbatim. Wiring updates: - `.github/workflows/python-tests.yml`: `pytest ... tests.py` → `python -m pytest ... tests/` (also switches to `python -m pytest` per the checkdmarc convention so cwd lands on the project root). - `pyproject.toml`: adds `[tool.pytest.ini_options] testpaths = ["tests"]` and `[tool.coverage.run] source = ["parsedmarc"]` with an `omit` for `parsedmarc/resources/maps/*.py`. The maps scripts are maintainer-only batch tooling that ships out of the wheel; excluding them from coverage makes the headline number reflect only installed library code. Runtime coverage on the new layout is 59% (was 45% with maps counted), and PR-B will push it to 90%+. - `AGENTS.md`: documents the new layout and how to run individual files / tests; tells future contributors not to reintroduce a monolithic tests.py. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com> * Restore 66.9% coverage baseline (count tests/ + parsedmarc) Master's headline 66.9% number on Codecov includes the tests.py file itself (99.35% covered) being measured alongside parsedmarc/*. The original tests.py had no `[tool.coverage.run]` block, so coverage's default — "measure every file imported during the run" — counted the test code as if it were product code. The split commit added `source = ["parsedmarc"]` which suppressed measurement of the test files (correct in principle, since test files aren't shipped code), and that alone made the headline number drop by ~8 percentage points without any actual loss of testing. This commit swaps `source` for an explicit `include = ["parsedmarc/*", "tests/*"]` so both halves are measured the way they were on master. Verified: 276 tests, 66.96% line coverage (effectively unchanged from master's 66.90%). If you want the shipped-code-only number (was the headline that this commit overrides), run `pytest --cov=parsedmarc tests/`. That number is currently 59% and is the focus of the upcoming coverage-expansion PR. Also adds junit.xml to .gitignore so the CI artefact doesn't get accidentally committed. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com> * Restrict coverage to shipped code (`source = ["parsedmarc"]`) Reverts the prior commit's `include = ["tests/*"]`. Counting the test files toward coverage was wrong — it conflates "shipped code exercised by tests" with "test code that pytest auto-runs", inflates the headline number, and rewards writing more tests rather than tests that verify more code. Master's apparent 66.9% was an artefact of the old monolithic tests.py having no [tool.coverage.run] block at all; coverage's default behaviour measured every imported file, including the test file itself at ~99% "covered", which added ~8 percentage points to the displayed number without any real testing signal. Restricting to `source = ["parsedmarc"]` plus the existing maps omit gives a meaningful baseline: 59% of shipped code is exercised by the test suite today. That's the number the next PR is targeting to lift to 90%+ before the 10.0.0 release; the Codecov "drop" here is a measurement correction, not a regression. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com> --------- Co-authored-by: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
parsedmarc
![]()
![]()


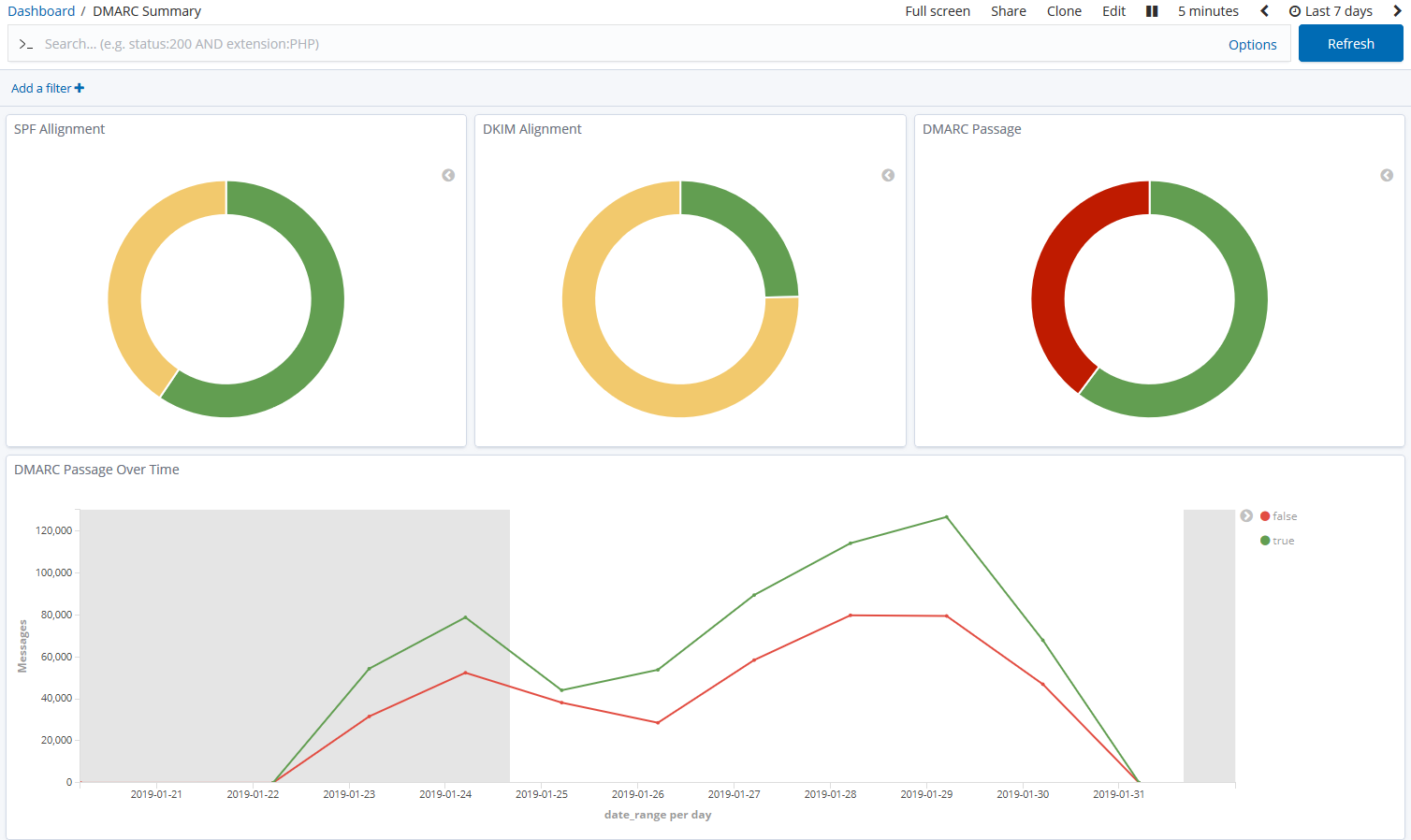
parsedmarc is a Python module and CLI utility for parsing DMARC
reports. When used with Elasticsearch and Kibana (or Splunk), it works
as a self-hosted open-source alternative to commercial DMARC report
processing services such as Agari Brand Protection, Dmarcian, OnDMARC,
ProofPoint Email Fraud Defense, and Valimail.
Note
Domain-based Message Authentication, Reporting, and Conformance (DMARC) is an email authentication protocol.
Sponsors
This is a project is maintained by one developer. Please consider sponsoring my work if you or your organization benefit from it.
Features
- Parses draft and 1.0 standard aggregate/rua DMARC reports
- Parses forensic/failure/ruf DMARC reports
- Parses reports from SMTP TLS Reporting
- Can parse reports from an inbox over IMAP, Microsoft Graph, or Gmail API
- Transparently handles gzip or zip compressed reports
- Consistent data structures
- Simple JSON and/or CSV output
- Optionally email the results
- Optionally send the results to Elasticsearch, Opensearch, and/or Splunk, for use with premade dashboards
- Optionally send reports to Apache Kafka
Python Compatibility
This project supports the following Python versions, which are either actively maintained or are the default versions for RHEL or Debian.
| Version | Supported | Reason |
|---|---|---|
| < 3.6 | ❌ | End of Life (EOL) |
| 3.6 | ❌ | Used in RHEL 8, but not supported by project dependencies |
| 3.7 | ❌ | End of Life (EOL) |
| 3.8 | ❌ | End of Life (EOL) |
| 3.9 | ❌ | Used in Debian 11 and RHEL 9, but not supported by project dependencies |
| 3.10 | ✅ | Actively maintained |
| 3.11 | ✅ | Actively maintained; supported until June 2028 (Debian 12) |
| 3.12 | ✅ | Actively maintained; supported until May 2035 (RHEL 10) |
| 3.13 | ✅ | Actively maintained; supported until June 2030 (Debian 13) |
| 3.14 | ✅ | Supported (requires imapclient>=3.1.0) |