mirror of
https://github.com/domainaware/parsedmarc.git
synced 2026-06-11 13:09:44 +00:00
A meaningful share of KU domains return a Cloudflare / DDoS-Guard / "Are you a robot?" / px-captcha interstitial instead of real homepage content — even after the curl-style relaxed-TLS fallback runs. For those rows we have neither homepage signal nor (often) a usable as_name, and they fall through to KU even though the operator is a real (often well-known) business that the classifier could trivially handle if it could just see the page. Added an opt-in `--use-search-fallback` flag that asks DuckDuckGo for `site:<domain>` when the homepage fetch returned a bot-block / parking / empty result, and uses the top result's title and description (only if the result host belongs to the input domain — anti-SEO-spam guard). Mechanism - New optional `ddgs` dependency, listed under the `[build]` extras. `from ddgs import DDGS` is wrapped in a try/except — the script runs without ddgs installed as long as `--use-search-fallback` isn't passed; the flag check exits with a helpful install message otherwise. - `_SEARCH_FALLBACK_TRIGGER_RE` — title/description patterns that look like a bot-block / WAF interstitial / parked / placeholder. Triggers the fallback. Same shape as the classifier's TITLE_NOISE_RE / PARKED_PAGE_RE; the search fallback is the recovery path for exactly the rows that filter excludes. - `_looks_bot_blocked()` — combined check: trigger regex matches OR title and description are both empty (typical of WAF interstitials that strip <title>/<meta> entirely). - `_hosts_match()` — same-domain SEO-spam guard. A search result is accepted only when its host is exactly the input domain or a subdomain of it. Third-party SEO-spam pages that scraped the domain name are silently skipped. - `_search_fallback_fetch()` — runs `site:<domain>` through DDG, walks results in rank order, returns the first one whose host passes the guard. Returns empty if no result matches (caller leaves the row's homepage data alone in that case). - `_collect_one()` now takes a `use_search_fallback` flag, calls the fallback after the homepage fetch when the homepage looks bot-blocked, and writes `title_source = "homepage"` or `"search"` so reviewers can audit which rows came from where. - New `title_source` column in the TSV. Smoke test Test set: bbc.com (real homepage, no fallback expected) plus 5 known Cloudflare-walled rows (1800contacts.com, americaneagle.com, broadwaytechnology.com, health.gov.il, mfa.gov.il). Result: bbc.com classified via homepage; the other 5 all recovered title + description via search and got `title_source=search`. The same-domain guard validated independently — for broadwaytechnology.com the guard correctly rejects bloomberg.com and accepts support.broadwaytechnology.com (broadway was acquired by Bloomberg, but the search fallback returns the broadway-domain snippet, not the parent's bloomberg.com product page). Caveats codified in AGENTS.md - Search snippets are still untrusted text (data-not-instructions rule applies the same way it does to homepage HTML). - DDG's index can lag a homepage rebrand by months — when a row classified via `title_source=search` disagrees with a fresh manual fetch, prefer the manual verification. The fallback is a recovery aid, not a tiebreaker against fresh content. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
parsedmarc
![]()
![]()


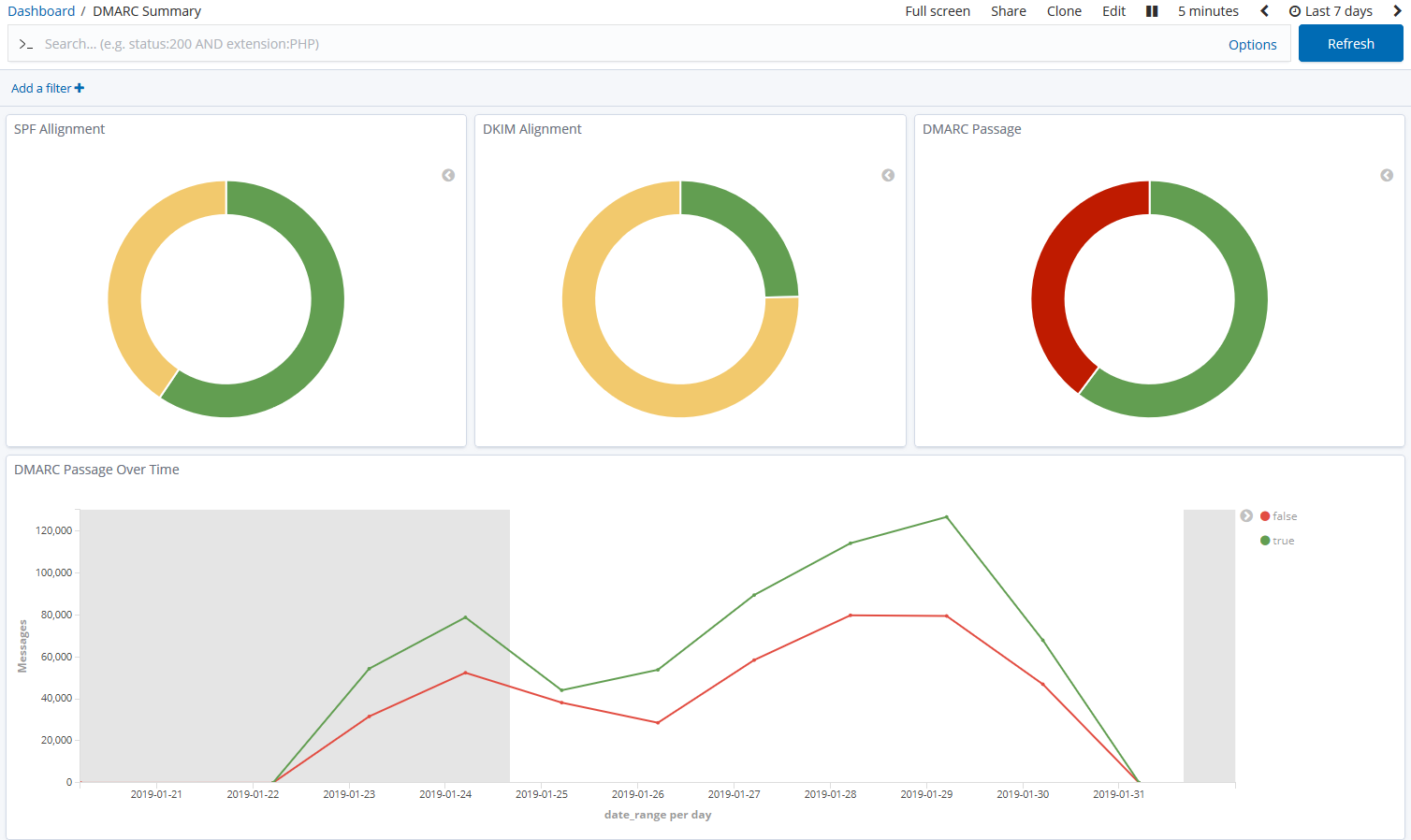
parsedmarc is a Python module and CLI utility for parsing DMARC
reports. When used with Elasticsearch and Kibana (or Splunk), it works
as a self-hosted open-source alternative to commercial DMARC report
processing services such as Agari Brand Protection, Dmarcian, OnDMARC,
ProofPoint Email Fraud Defense, and Valimail.
Note
Domain-based Message Authentication, Reporting, and Conformance (DMARC) is an email authentication protocol.
Sponsors
This is a project is maintained by one developer. Please consider sponsoring my work if you or your organization benefit from it.
Features
- Parses draft and 1.0 standard aggregate/rua DMARC reports
- Parses forensic/failure/ruf DMARC reports
- Parses reports from SMTP TLS Reporting
- Can parse reports from an inbox over IMAP, Microsoft Graph, or Gmail API
- Transparently handles gzip or zip compressed reports
- Consistent data structures
- Simple JSON and/or CSV output
- Optionally email the results
- Optionally send the results to Elasticsearch, Opensearch, and/or Splunk, for use with premade dashboards
- Optionally send reports to Apache Kafka
Python Compatibility
This project supports the following Python versions, which are either actively maintained or are the default versions for RHEL or Debian.
| Version | Supported | Reason |
|---|---|---|
| < 3.6 | ❌ | End of Life (EOL) |
| 3.6 | ❌ | Used in RHEL 8, but not supported by project dependencies |
| 3.7 | ❌ | End of Life (EOL) |
| 3.8 | ❌ | End of Life (EOL) |
| 3.9 | ❌ | Used in Debian 11 and RHEL 9, but not supported by project dependencies |
| 3.10 | ✅ | Actively maintained |
| 3.11 | ✅ | Actively maintained; supported until June 2028 (Debian 12) |
| 3.12 | ✅ | Actively maintained; supported until May 2035 (RHEL 10) |
| 3.13 | ✅ | Actively maintained; supported until June 2030 (Debian 13) |
| 3.14 | ✅ | Supported (requires imapclient>=3.1.0) |