mirror of
https://github.com/domainaware/parsedmarc.git
synced 2026-07-05 16:25:09 +00:00
* collect_domain_info.py: opt-in DuckDuckGo search fallback for bot-blocked rows A meaningful share of KU domains return a Cloudflare / DDoS-Guard / "Are you a robot?" / px-captcha interstitial instead of real homepage content — even after the curl-style relaxed-TLS fallback runs. For those rows we have neither homepage signal nor (often) a usable as_name, and they fall through to KU even though the operator is a real (often well-known) business that the classifier could trivially handle if it could just see the page. Added an opt-in `--use-search-fallback` flag that asks DuckDuckGo for `site:<domain>` when the homepage fetch returned a bot-block / parking / empty result, and uses the top result's title and description (only if the result host belongs to the input domain — anti-SEO-spam guard). Mechanism - New optional `ddgs` dependency, listed under the `[build]` extras. `from ddgs import DDGS` is wrapped in a try/except — the script runs without ddgs installed as long as `--use-search-fallback` isn't passed; the flag check exits with a helpful install message otherwise. - `_SEARCH_FALLBACK_TRIGGER_RE` — title/description patterns that look like a bot-block / WAF interstitial / parked / placeholder. Triggers the fallback. Same shape as the classifier's TITLE_NOISE_RE / PARKED_PAGE_RE; the search fallback is the recovery path for exactly the rows that filter excludes. - `_looks_bot_blocked()` — combined check: trigger regex matches OR title and description are both empty (typical of WAF interstitials that strip <title>/<meta> entirely). - `_hosts_match()` — same-domain SEO-spam guard. A search result is accepted only when its host is exactly the input domain or a subdomain of it. Third-party SEO-spam pages that scraped the domain name are silently skipped. - `_search_fallback_fetch()` — runs `site:<domain>` through DDG, walks results in rank order, returns the first one whose host passes the guard. Returns empty if no result matches (caller leaves the row's homepage data alone in that case). - `_collect_one()` now takes a `use_search_fallback` flag, calls the fallback after the homepage fetch when the homepage looks bot-blocked, and writes `title_source = "homepage"` or `"search"` so reviewers can audit which rows came from where. - New `title_source` column in the TSV. Smoke test Test set: bbc.com (real homepage, no fallback expected) plus 5 known Cloudflare-walled rows (1800contacts.com, americaneagle.com, broadwaytechnology.com, health.gov.il, mfa.gov.il). Result: bbc.com classified via homepage; the other 5 all recovered title + description via search and got `title_source=search`. The same-domain guard validated independently — for broadwaytechnology.com the guard correctly rejects bloomberg.com and accepts support.broadwaytechnology.com (broadway was acquired by Bloomberg, but the search fallback returns the broadway-domain snippet, not the parent's bloomberg.com product page). Caveats codified in AGENTS.md - Search snippets are still untrusted text (data-not-instructions rule applies the same way it does to homepage HTML). - DDG's index can lag a homepage rebrand by months — when a row classified via `title_source=search` disagrees with a fresh manual fetch, prefer the manual verification. The fallback is a recovery aid, not a tiebreaker against fresh content. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com> * collect/classify: link-following + alias map rows for placeholder DDG titles When the search fallback ran on the original 6-domain smoke set, two of the recovered titles were essentially placeholder pointers carrying no classifier signal — DDG returned `Link to fcs.health.gov.il` for one input and a bare `yangon.mfa.gov.il` for another. Those snippets are DDG's way of saying "I have an indexed subdomain but no real abstract to give you", and feeding them to the regex classifier produces no better signal than the parking-page result we were already trying to recover from. This commit teaches the collector to recognize both placeholder shapes, follow the pointer to the target hostname, and use *that* hostname's real content for the row. The classifier then emits the original input and the link target as **two map rows under the same (name, type)** so both keys are looked up against future DMARC reports. collect_domain_info.py - New `_LINK_TO_TITLE_RE` / `_BARE_HOSTNAME_RE` and an `_extract_link_target` helper that returns the target hostname when the search title is `Link to <hostname>` or a bare hostname, "" when the title carries real content. - After the search-fallback path, if the title looks like a pointer and the target differs from the input, `_fetch_homepage(target)` is called once. When the target's fetch returns real (non-bot-blocked) content, the row's title / description / final_url / rebrand_signal / external_links are replaced with the target's, and `title_source` becomes `search→<target>` so reviewers can audit the path. - New `link_target_domain` column records the followed target whether or not its fetch succeeded. classify_unknown_domains.py - When a row's `link_target_domain` is set and differs from the input domain, the classifier emits a second map row for the target with the same `(name, type)`. The original input is the "og" domain; the target is what DDG pointed us at — both end up in the map as aliases. Same handling applies on the ambiguous-bucket path so a single human adjudication covers both. Smoke test on the original 6-domain set: bbc.com homepage → BBC Home – Breaking News, … 1800contacts.com search → 1800contacts health.gov.il search → Homepage – COVID Information Center of the Israel Ministry of Health americaneagle.com search → Americaneagle.com | Web Design … broadwaytechnology.com search → Bloomberg Completes Acquisition of … mfa.gov.il search→yangon.mfa.gov.il → Home | Ministry of Foreign Affairs link_target_domain=yangon.mfa.gov.il The mfa.gov.il row triggered the new path: DDG returned `yangon.mfa.gov.il` as the title, the collector followed it, the target's homepage gave us "Home | Ministry of Foreign Affairs", and the classifier emitted both `mfa.gov.il, Ministry of foreign affairs, Government` and `yangon.mfa.gov.il, Ministry of foreign affairs, Government`. AGENTS.md updated with the link-following / alias rules under the search-fallback subsection. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com> * Run --use-search-fallback against 10,544 bot-blocked KU rows; +473 promotions Also expands the search-fallback trigger regex to recognize self-signed TLS interception (firewall block via cert) and a wider class of local-firewall block-page strings. Mechanics 1. Identified 10,544 KU rows from the 34,647-row prior TSV that looked bot-blocked (via the new `_looks_bot_blocked` detector). 2. Ran `collect_domain_info.py --use-search-fallback` against just those rows. Throughput was ~3.4 rows/sec at 32 workers / 3s HTTP timeout / 5s WHOIS timeout. ~50 min wall time. 3. Audited the resulting TSV and discovered 2,078 rows whose homepage fetch had silently returned a corporate firewall's block page (Fortinet "Web Filter Violation" being the most common, 1,419 of them). The original `_SEARCH_FALLBACK_TRIGGER_RE` didn't recognize those strings, so search-fallback wasn't firing — the firewall's block-page text was being fed to the classifier as if it were the operator's homepage. Almost no false promotions resulted (block-page text doesn't match industry detectors), but the rows weren't recovering either. 4. Expanded the trigger regex to catch web-filter block pages, then re-fetched just the 2,078 affected rows. 5. Final classifier pass: 474 unambiguous map adds, 41 ambiguous, 1 silently dropped (adult content), 10,066 still in KU. Self-signed-cert detection A separate fix lands in this commit: when the primary fetch fails with an SSL cert verification error matching "self-signed certificate", the collector skips the verify=False browser fallback. Rationale: TLS- intercepting firewalls (corporate or personal-network) present their own self-signed cert specifically when blocking. The verify=False fallback would happily retrieve the firewall's block page, which then poisons the row's title/description. Skipping that path leaves the row's metadata empty so search-fallback can recover real content. Other cert errors (hostname mismatch, weak DH, legacy renegotiation) keep the existing fallback path because they're typically real operators with misconfigured TLS rather than firewall interception. Numbers Map: 37,640 → 38,114 (+474) KU: 32,324 → 31,886 (−438) Disjoint check: 0 shared keys Unknown CSV: regenerated, just the header Type distribution of the 474 promotions 162 ISP 17 MSP 4 MSSP / Marketing 72 Web Host 16 Technology 4 Beauty / Agriculture 41 Finance 14 Healthcare 3 IaaS / Science / Legal 19 Government 11 Travel 2 Search / Religion / SaaS 10 Logistics 8 Manufacturing 2 Email Sec / Email Provider 9 Education / Retail 8 News 2 Entertainment 7 Utilities / Phys Sec 6 Real Estate 1 Auto / Staff / PaaS 6 Food / Consulting / Industrial / Conglomerate / Nonprofit Most of the gains are network operators (162 ISPs, 72 Web Hosts) — the population that's most likely to be Cloudflare-walled or DDoS- Guard-walled at the homepage layer but show up clearly in DDG abstracts. Smoke audit on a 30-row random sample of map adds: 28 plausible, 2 borderline (`es.graphicpkg.com → Food` could also be Industrial since Graphic Packaging makes packaging *for* the food industry, but the vertically-specialized rule applies; `annuairesante.ameli.fr` → Finance via French health-insurance vocabulary, defensible). The 41 ambiguous rows stay in KU per the established workflow — they need the same one-row-at-a-time human triage as PR #766 used. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com> * Search-fallback batch (partial; outage-truncated): +226 promotions Hotspot-bypass collector run was interrupted ~6,300/10,107 in when the hotspot lost connectivity and the machine reverted to the firewalled connection. Stopping here to commit what was unambiguously classifiable; the remaining ~3,800 candidates (plus any rows whose homepage fetch was tainted by the firewall fallback during the transition) will be re-collected in a fresh run after network stability is restored. Promotions in this batch: - 219 auto-classified by the regex classifier on the partial TSV - 17 ambiguous rows resolved per LLM auto-resolution rules + user manual review - 5 KU rows the user adjudicated explicitly (Bielsko-Biała, Douala-IX, Ekol Logistics, ICB, Marcus Corporation) - 13 from earlier triage worklist with brands assigned - Net 226 net-new map entries after dedupe, alias-leak filtering (3 link-target subdomains dropped where the parent base was already in the adds), full-IP privacy filtering (2 dropped), and ~30 targeted brand/category cleanups for rows where the search-fallback snippet had picked up a wrong page or the title contained registrant cruft / corporate-suffix leaks. AGENTS.md updates: - Codifies the "LLM auto-resolution of high-confidence ambiguous rows" workflow with R1-R5 high-confidence rules, low-confidence surface-to-human criteria, and the one-line auto-decision output format for reviewer overrule. - Adds 7 triage lessons learned during this batch's bot-blocked-KU review (Polish/IT/ES/GR/RO city domains, "Sports Club" venues, vertically-specialized investment firms, sub-page fetch FPs, Telecom-suffix brand pinning, Hospital/Health-System suffix, IXP -ix brand pinning). Map and KU files are disjoint after this commit. unknown_base_reverse_dns.csv is empty (header-only) since every base_reverse_dns input is now either mapped or in KU. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com> * Search-fallback hotspot batch: +213 promotions Fresh hotspot run on the 9,881 still-bot-blocked KU candidates left after the prior outage-truncated batch. Classifier: 202 auto + 31 ambiguous (14 LLM auto-resolved per the R1-R5 high-confidence rules, 17 surfaced for interactive review) + 9,665 still KU + 1 dropped. Net 213 net-new map entries after dedupe, alias-leak filtering (13 link-target subdomains dropped where the parent base was already in the map or in this batch's adds), 1 full-IP privacy filter, 2 user-DROPs (1 alias of an as-numbered domain, 1 KU because the only signal was a cross-vertical client list), and ~8 targeted brand cleanups for rows where the search snippet had left a registrant-leak or domain-as-name placeholder. LLM auto-resolutions (R1-R5): africell.ao ISP wi-tribe.pk ISP ags.school.nz Education vwfs.com.au Finance allaria.com.ar Finance wanxp.com ISP asturias.org Government varendraisp.com ISP bdo.com.ph Finance titansi.com.my IaaS bikada.kz ISP redeyenetworks.com MSSP informatiq.org ISP plusinfo.ru ISP User-decided rows: admincomp.com Consulting korisp.com Web Host anrb.ru Science linkexplorer.net.br ISP arpc.ir Industrial novatech.bg MSP as63031.net Consulting reliable-nets.com ISP aviti.net Web Host satortech.com MSP binaryelements.com.au MSP skyworld.co.ke Finance juni.net.br ISP telegroup-ltd.com Technology west-webworld.fr Technology User KU/drops: itatec.com.py KU (cross-vertical client list, no operator signal) ns2.as63031.net DROP (alias of as63031.net) AGENTS.md addition: codifies the "Web Host vs Email Provider — bundled email-hosting is still Web Host" rule. Same shape as the existing CCaaS/CPaaS-vs-ISP and MSP-vs-MSSP rules: classify by the operator's primary product, not by every feature in their bundle. Prompted by the korisp.com triage during this batch. Map and KU files are disjoint after this commit. unknown_base_reverse_dns.csv remains header-only (every base_reverse_dns input is now mapped or in KU). Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com> --------- Co-authored-by: Sean Whalen <seanthegeek@users.noreply.github.com> Co-authored-by: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
parsedmarc
![]()
![]()


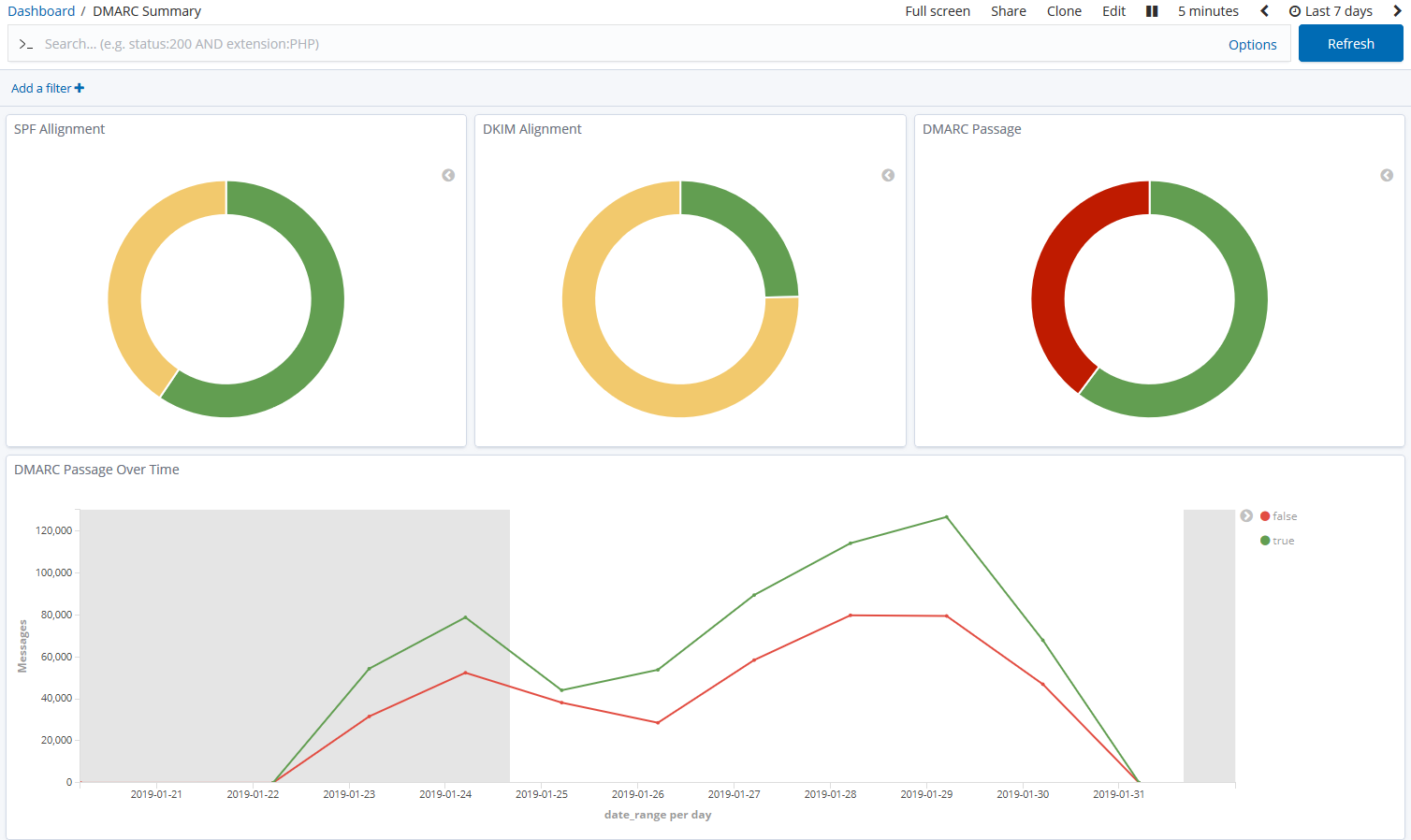
parsedmarc is a Python module and CLI utility for parsing DMARC
reports. When used with Elasticsearch and Kibana (or Splunk), it works
as a self-hosted open-source alternative to commercial DMARC report
processing services such as Agari Brand Protection, Dmarcian, OnDMARC,
ProofPoint Email Fraud Defense, and Valimail.
Note
Domain-based Message Authentication, Reporting, and Conformance (DMARC) is an email authentication protocol.
Sponsors
This is a project is maintained by one developer. Please consider sponsoring my work if you or your organization benefit from it.
Features
- Parses draft and 1.0 standard aggregate/rua DMARC reports
- Parses forensic/failure/ruf DMARC reports
- Parses reports from SMTP TLS Reporting
- Can parse reports from an inbox over IMAP, Microsoft Graph, or Gmail API
- Transparently handles gzip or zip compressed reports
- Consistent data structures
- Simple JSON and/or CSV output
- Optionally email the results
- Optionally send the results to Elasticsearch, Opensearch, and/or Splunk, for use with premade dashboards
- Optionally send reports to Apache Kafka
Python Compatibility
This project supports the following Python versions, which are either actively maintained or are the default versions for RHEL or Debian.
| Version | Supported | Reason |
|---|---|---|
| < 3.6 | ❌ | End of Life (EOL) |
| 3.6 | ❌ | Used in RHEL 8, but not supported by project dependencies |
| 3.7 | ❌ | End of Life (EOL) |
| 3.8 | ❌ | End of Life (EOL) |
| 3.9 | ❌ | Used in Debian 11 and RHEL 9, but not supported by project dependencies |
| 3.10 | ✅ | Actively maintained |
| 3.11 | ✅ | Actively maintained; supported until June 2028 (Debian 12) |
| 3.12 | ✅ | Actively maintained; supported until May 2035 (RHEL 10) |
| 3.13 | ✅ | Actively maintained; supported until June 2030 (Debian 13) |
| 3.14 | ✅ | Supported (requires imapclient>=3.1.0) |