* Chore(beta): add sqlite-vec 0.1.9 dependency Pinned exactly: the 0.1.9 wheels carry no baked SIMD flags (safe on pre-AVX2 CPUs, the point of this migration); the 0.1.10 alphas bake -mavx and would reintroduce the #12970 crash class. Co-Authored-By: Claude Sonnet 4.6 <noreply@anthropic.com> * Test(beta): port vector store tests to sqlite-vec backend Co-Authored-By: Claude Sonnet 4.6 <noreply@anthropic.com> * Enhancement(beta): switch AI vector store from LanceDB to sqlite-vec Fixes the non-AVX2 SIGILL class (#12970) at the root: lancedb is no longer imported. sqlite-vec 0.1.9 wheels carry no baked SIMD, vec0 metadata columns give parameterized EQ/IN filtering, WAL preserves the lock-free-reader model, and compact() rebuilds the table because vec0 DELETEs never reclaim space. Implementation notes vs. the Task 3A draft: - compact() uses a file-swap approach (new db file + Path.replace) rather than ALTER TABLE RENAME, which does not cascade to shadow tables in sqlite-vec 0.1.9 (upstream limitation). - Bloat is tracked via a cumulative total_inserts counter in index_meta because the _rowids shadow table does not accumulate deleted rows in 0.1.9 (contrary to the design doc assumption from #54). - None distances from the zero-vector cosine edge case are mapped to similarity 0.0 rather than raising TypeError. - Test suite updated accordingly: _bloat_ratio reads index_meta instead of _rowids; seed collision in force-compact test fixed (seed=100.0). Co-Authored-By: Claude Sonnet 4.6 <noreply@anthropic.com> * Enhancement(beta): wire indexing pipeline to the sqlite-vec store Co-Authored-By: Claude Sonnet 4.6 <noreply@anthropic.com> * Enhancement(beta): move filename/storage path/ASN to node metadata Same treatment as title/tags/correspondent in #12944: excluded from the embedded text, visible to the LLM via metadata prepend. Changes embedded text for every document, so it ships inside the sqlite-vec transition, whose forced rebuild re-embeds everything anyway. Co-Authored-By: Claude Sonnet 4.6 <noreply@anthropic.com> * Test(beta): cover legacy LanceDB index cleanup and forced rebuild Co-Authored-By: Claude Sonnet 4.6 <noreply@anthropic.com> * Chore(beta): drop lancedb dependency Fixes #12970: the package whose wheels SIGILL on non-AVX2 CPUs is no longer installed at all. Co-Authored-By: Claude Sonnet 4.6 <noreply@anthropic.com> * Chore(beta): partial pyrefly cleanup on sqlite-vec vector store - Add MetadataFilter import and isinstance guard in _build_where() - Add query_embedding None guard in query() - Fix dict.get() type-checker ambiguity in get_configured_model_name() Co-Authored-By: Claude Sonnet 4.6 <noreply@anthropic.com> * Chore(beta): drop automatic LanceDB index cleanup on startup Leave legacy Lance directory removal to the user rather than deleting it automatically on first run. Beta policy: user is expected to do a clean re-embed anyway; no need for the system to silently delete their data. Remove _cleanup_legacy_lance_index(), the forced-rebuild path that called it, and the associated tests. Co-Authored-By: Claude Sonnet 4.6 <noreply@anthropic.com> * Chore(beta): ruff format pass on sqlite-vec AI files Co-Authored-By: Claude Sonnet 4.6 <noreply@anthropic.com> * Removes the benchmarking file * Try to resolve or silence some semgrep. But we're using SQL here, not an ORM and we control the inputs, not users * Enhancement(beta): add schema migration machinery to sqlite-vec vector store Adds versioned schema migration support modelled after PR #12968's LanceDB approach, adapted for sqlite-vec's file-swap compaction pattern. - SCHEMA_VERSION = 1 written to index_meta at table creation and preserved through compact() - Migration dataclass with from_version, to_version, kind ("structural" or "re-embed"), description, and an optional apply(src, dst, dim) callable - MIGRATIONS registry (empty at v1 baseline); add entries and bump SCHEMA_VERSION when the schema changes - check_and_run_migrations(): structural migrations run via the same file-swap as compact() (no re-embed); re-embed migrations return True so the caller forces a full rebuild - update_llm_index() calls check_and_run_migrations() under the write lock before any indexing work Co-Authored-By: Claude Sonnet 4.6 <noreply@anthropic.com> * Chore(beta): deduplicate vector store internals via helper methods Extract three helpers to remove copy-paste between compact() and _run_structural_migration(): - _meta_set_on(conn, key, value): static upsert into any connection's index_meta; _meta_set() now delegates to it - _create_vec_table(conn, dim): CREATE VIRTUAL TABLE DDL (carries the nosemgrep annotation) - _swap_in_compact(compact_path, db_path): close/replace/reconnect sequence used by both file-swap callers Also normalises compact() error-path cleanup to unlink(missing_ok=True). Co-Authored-By: Claude Sonnet 4.6 <noreply@anthropic.com> * Adds equality test and no covers some defensive error handling stuff * Ensures an embed migration stops the migration chain, just in case * Silence one kind right but not really semgrep * Trims dead assignment * Fix(beta): address Copilot review on sqlite-vec vector store Three findings from the PR review: - compact() failure cleanup now unlinks the temporary .compact-wal and .compact-shm files, matching _run_structural_migration(); previously only the main .compact file was removed. - _build_where() fails closed (1 = 0) when filters are requested but none translate, instead of emitting "()" which is invalid SQL; filters scope document access, so an empty translation must match no rows. - Drop the unused table_name constructor parameter (all SQL hardcodes DEFAULT_TABLE_NAME) and its callers in indexing.py. Co-Authored-By: Claude Opus 4.8 <noreply@anthropic.com> * Enhancement(beta): guard sqlite-vec compaction swap against concurrent readers The compaction/migration file swap replaces the database via os.replace, but the -wal/-shm files are keyed by path, not inode. A reader holding an open connection across the swap leaves the old WAL aliased onto the new file; a subsequent write then corrupts the database (reproduced via PRAGMA integrity_check). Add a cross-process read/write lock (filelock.ReadWriteLock) over the index: - read_store() holds it shared for the whole connection lifetime (and closes the connection on exit); concurrent readers do not block. - compaction and the migration check run under an exclusive lock that drains readers, and skip with an info log on Timeout (maintenance op, retries next run). - Normal writes are untouched: WAL gives reader/writer concurrency and LLM_INDEX_LOCK still serializes writers, so they never block readers. load_or_build_index() now takes the store from the caller's read_store() so the lock and connection span the whole retrieval; chat holds it across the streamed response. Two new settings: LLM_INDEX_RWLOCK and LLM_INDEX_COMPACTION_LOCK_TIMEOUT. Co-Authored-By: Claude Opus 4.8 <noreply@anthropic.com> * Ensures the store alays cleans up SQLite connections for any operations, even on errors --------- Co-authored-by: Claude Sonnet 4.6 <noreply@anthropic.com>
![]()


![]()
![]()

![]()
Paperless-ngx
Paperless-ngx is a document management system that transforms your physical documents into a searchable online archive so you can keep, well, less paper.
Paperless-ngx is the official successor to the original Paperless & Paperless-ng projects and is designed to distribute the responsibility of advancing and supporting the project among a team of people. Consider joining us!
Thanks to the generous folks at DigitalOcean, a demo is available at demo.paperless-ngx.com using login demo / demo. Note: demo content is reset frequently and confidential information should not be uploaded.
This project is supported by:
![]()
Features
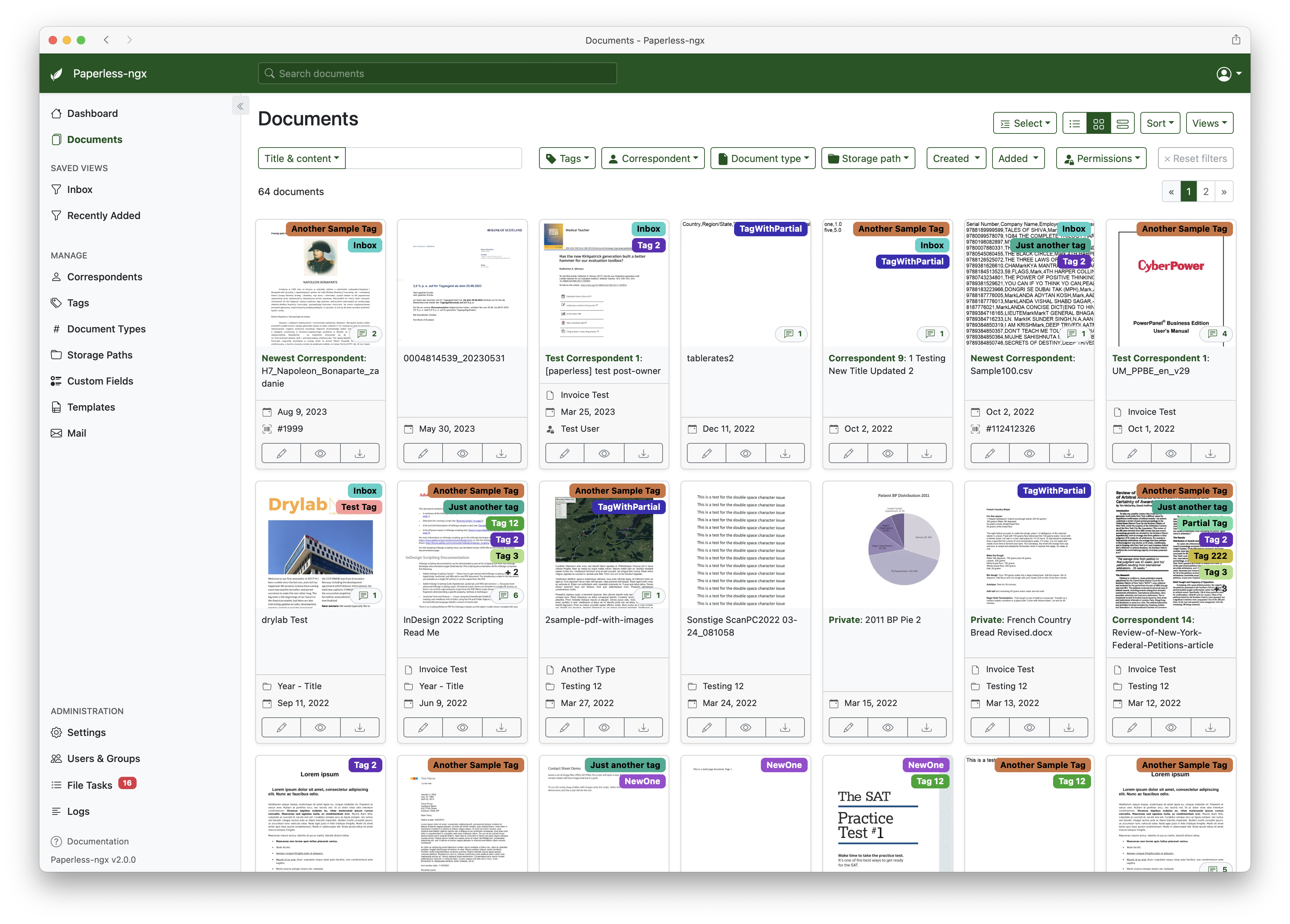
A full list of features and screenshots are available in the documentation.
Getting started
The easiest way to deploy paperless is docker compose. The files in the /docker/compose directory are configured to pull the image from the GitHub container registry.
If you'd like to jump right in, you can configure a docker compose environment with our install script:
bash -c "$(curl -L https://raw.githubusercontent.com/paperless-ngx/paperless-ngx/main/install-paperless-ngx.sh)"
More details and step-by-step guides for alternative installation methods can be found in the documentation.
Migrating from Paperless-ng is easy, just drop in the new docker image! See the documentation on migrating for more details.
Documentation
The documentation for Paperless-ngx is available at https://docs.paperless-ngx.com.
Contributing
If you feel like contributing to the project, please do! Bug fixes, enhancements, visual fixes etc. are always welcome. If you want to implement something big: Please start a discussion about that! The documentation has some basic information on how to get started.
Community Support
People interested in continuing the work on paperless-ngx are encouraged to reach out here on github and in the Matrix Room. If you would like to contribute to the project on an ongoing basis there are multiple teams (frontend, ci/cd, etc) that could use your help so please reach out!
Translation
Paperless-ngx is available in many languages that are coordinated on Crowdin. If you want to help out by translating paperless-ngx into your language, please head over to https://crowdin.com/project/paperless-ngx, and thank you! More details can be found in CONTRIBUTING.md.
Feature Requests
Feature requests can be submitted via GitHub Discussions, you can search for existing ideas, add your own and vote for the ones you care about.
Bugs
For bugs please open an issue or start a discussion if you have questions.
Related Projects
Please see the wiki for a user-maintained list of related projects and software that is compatible with Paperless-ngx.
Important Note
Document scanners are typically used to scan sensitive documents like your social insurance number, tax records, invoices, etc. Paperless-ngx should never be run on an untrusted host because information is stored in clear text without encryption. No guarantees are made regarding security (but we do try!) and you use the app at your own risk. The safest way to run Paperless-ngx is on a local server in your own home with backups in place.