* Fix: Move LLM index lock outside index dir and skip per-doc tasks on bulk update Two concurrency bugs from #12893: [P1] Lock file lived inside LLM_INDEX_DIR. A rebuild calls shutil.rmtree(LLM_INDEX_DIR), deleting the lock while a worker still held it. A second worker then acquired a fresh lock on the new path and ran concurrently, defeating serialisation. Move the lock to DATA_DIR/locks/llm_index.lock (a new settings constant LLM_INDEX_LOCK) so rmtree cannot touch it. The locks/ dir is created at settings load time, matching the existing pattern for LOGGING_DIR. [P2] document_updated was connected to add_or_update_document_in_llm_index in apps.py. bulk_update_documents() emits document_updated for every document in the batch, queuing N per-document LLM tasks, and then also calls update_llm_index(rebuild=False) once at the end. Pass skip_ai_index=True when sending document_updated from the bulk path so the handler skips the per-document enqueue; the existing batch call at the end of bulk_update_documents is the only LLM update for that path. Co-Authored-By: Claude Sonnet 4.6 <noreply@anthropic.com> * Fix: ghost vectors leave KeyError-prone nodes_dict entries after deletion docstore.delete_document() removes a node from the docstore but leaves its entry in index_struct.nodes_dict (the FAISS positional-id to node-UUID map). A subsequent similarity query resolves the ghost position to the deleted UUID, finds nothing in fetched_nodes_by_id, and raises KeyError inside _insert_fetched_nodes_into_query_result. Purge stale nodes_dict entries after each docstore deletion and re-sync the mutated index_struct into the kvstore so persist() writes the updated mapping. Dead FAISS vectors remain in the flat index until the next full rebuild (IndexFlatL2 is append-only); add a try/except KeyError around retriever.retrieve() as a defensive fallback for any residual ghost positions. Co-Authored-By: Claude Sonnet 4.6 <noreply@anthropic.com> * Fix: acquire index lock in query_similar_documents query_similar_documents() loaded the index and ran the FAISS retriever without holding the file lock. All write paths (update_llm_index, llm_index_add_or_update_document, llm_index_remove_document) hold FileLock(_index_lock_path()), so a concurrent rebuild calling shutil.rmtree(LLM_INDEX_DIR) while a read is mid-load produces an IOError or corrupt partial state. Wrap the load_or_build_index() call and all subsequent retriever work inside FileLock. The early-return guards (vector_store_file_exists check, empty allowed_document_ids) remain outside the lock; the DB query for the final result set also stays outside. Co-Authored-By: Claude Sonnet 4.6 <noreply@anthropic.com> * Fix: skip LLM index enqueue on document_updated during version addition When a document is consumed as a new version of an existing document, the consumer fires document_consumption_finished (which triggers add_or_update_document_in_llm_index) and then document_updated for the root document. Both signals are connected to the same handler, so the root document was enqueued for LLM indexing twice per version-addition event. Pass skip_ai_index=True on the consumer's version-addition document_updated send so the handler's existing guard suppresses the duplicate enqueue. Co-Authored-By: Claude Sonnet 4.6 <noreply@anthropic.com> * Test: bulk_update_documents must not enqueue per-doc LLM tasks With AI enabled, bulk_update_documents() sends document_updated for every document in the batch. The skip_ai_index=True kwarg (added in the P2 fix) prevents add_or_update_document_in_llm_index from enqueuing a per-document task for each one. Only the single update_llm_index call at the end should run. Co-Authored-By: Claude Sonnet 4.6 <noreply@anthropic.com> * Debug level log sure * Update src/paperless_ai/indexing.py Co-authored-by: shamoon <4887959+shamoon@users.noreply.github.com> * Apply suggestion from @shamoon --------- Co-authored-by: Claude Sonnet 4.6 <noreply@anthropic.com> Co-authored-by: shamoon <4887959+shamoon@users.noreply.github.com>
![]()


![]()
![]()

![]()
Paperless-ngx
Paperless-ngx is a document management system that transforms your physical documents into a searchable online archive so you can keep, well, less paper.
Paperless-ngx is the official successor to the original Paperless & Paperless-ng projects and is designed to distribute the responsibility of advancing and supporting the project among a team of people. Consider joining us!
Thanks to the generous folks at DigitalOcean, a demo is available at demo.paperless-ngx.com using login demo / demo. Note: demo content is reset frequently and confidential information should not be uploaded.
This project is supported by:
![]()
Features
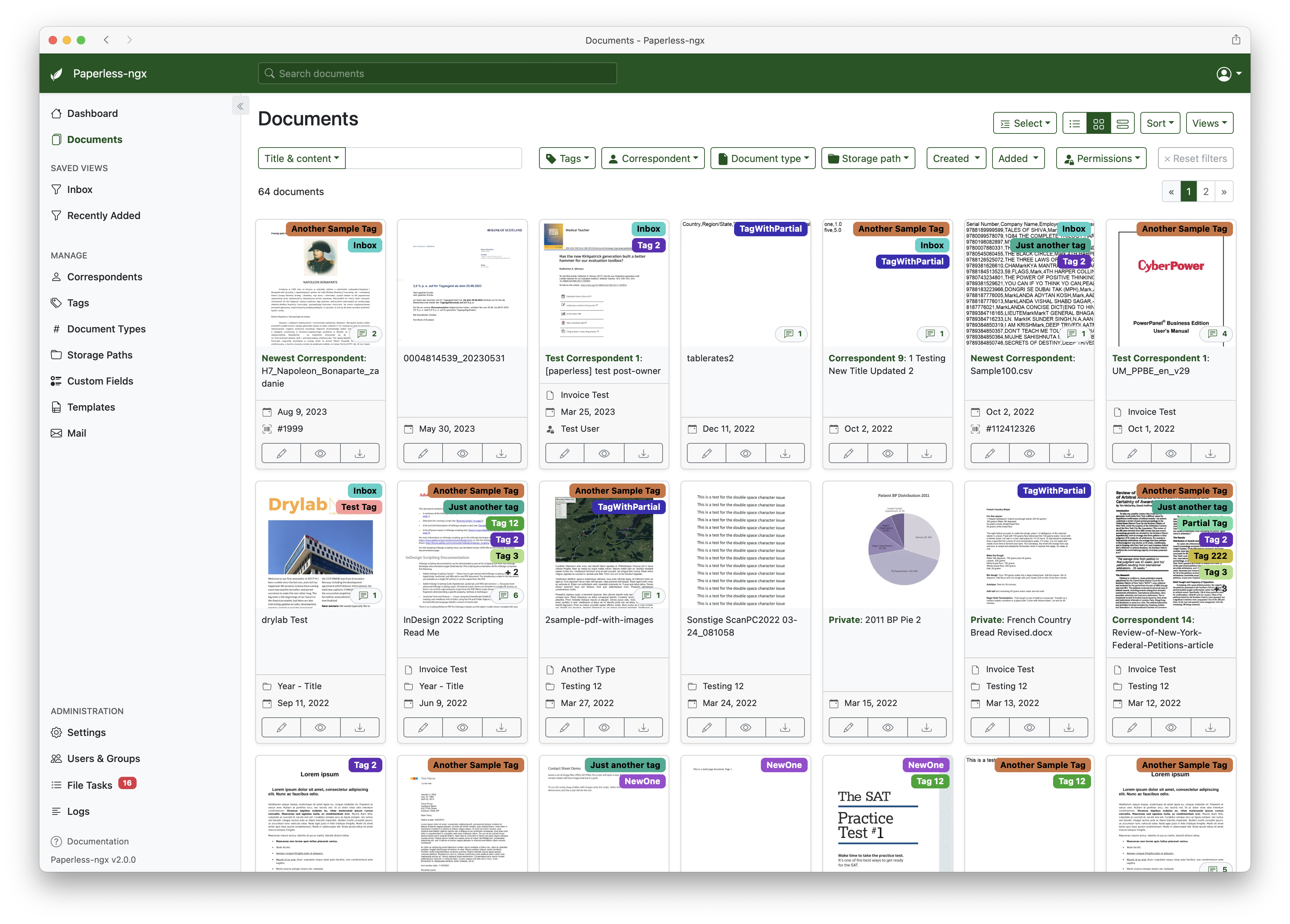
A full list of features and screenshots are available in the documentation.
Getting started
The easiest way to deploy paperless is docker compose. The files in the /docker/compose directory are configured to pull the image from the GitHub container registry.
If you'd like to jump right in, you can configure a docker compose environment with our install script:
bash -c "$(curl -L https://raw.githubusercontent.com/paperless-ngx/paperless-ngx/main/install-paperless-ngx.sh)"
More details and step-by-step guides for alternative installation methods can be found in the documentation.
Migrating from Paperless-ng is easy, just drop in the new docker image! See the documentation on migrating for more details.
Documentation
The documentation for Paperless-ngx is available at https://docs.paperless-ngx.com.
Contributing
If you feel like contributing to the project, please do! Bug fixes, enhancements, visual fixes etc. are always welcome. If you want to implement something big: Please start a discussion about that! The documentation has some basic information on how to get started.
Community Support
People interested in continuing the work on paperless-ngx are encouraged to reach out here on github and in the Matrix Room. If you would like to contribute to the project on an ongoing basis there are multiple teams (frontend, ci/cd, etc) that could use your help so please reach out!
Translation
Paperless-ngx is available in many languages that are coordinated on Crowdin. If you want to help out by translating paperless-ngx into your language, please head over to https://crowdin.com/project/paperless-ngx, and thank you! More details can be found in CONTRIBUTING.md.
Feature Requests
Feature requests can be submitted via GitHub Discussions, you can search for existing ideas, add your own and vote for the ones you care about.
Bugs
For bugs please open an issue or start a discussion if you have questions.
Related Projects
Please see the wiki for a user-maintained list of related projects and software that is compatible with Paperless-ngx.
Important Note
Document scanners are typically used to scan sensitive documents like your social insurance number, tax records, invoices, etc. Paperless-ngx should never be run on an untrusted host because information is stored in clear text without encryption. No guarantees are made regarding security (but we do try!) and you use the app at your own risk. The safest way to run Paperless-ngx is on a local server in your own home with backups in place.