mirror of
https://github.com/domainaware/parsedmarc.git
synced 2026-05-25 21:35:22 +00:00
* fix: import OpenSearch dashboards into the real Global tenant dashboard-dev-bootstrap.sh sent `securitytenant: global_tenant`. The OpenSearch security plugin reads that header as a tenant *name*, and `global_tenant` is a sample custom tenant from the security demo config -- not the shared Global tenant, whose token is the literal `global`. The import therefore landed in a separate `global_tenant` tenant (its own `.kibana_<hash>_globaltenant_1` index) and the dashboards were invisible to anyone viewing the Global tenant in OpenSearch Dashboards. Verified against the live dev cluster: `_find` under `securitytenant: global` returned 26 objects and `.kibana_1` (the Global tenant index the UI reads) went from 2 to 67 docs after re-importing with the fix. An empty/omitted header read 0 from Global -- it falls back to the user's configured default tenant -- so `global` is the only reliable token. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com> * fix: don't drop report files whose names contain glob metacharacters The CLI expanded every file argument with glob(), which treats [, ], *, and ? as pattern syntax. A literal path like "[Netease DMARC Failure Report] Rent Reminder.eml" -- the bracketed shape many providers use for emailed failure reports -- was read as a character class, matched nothing, and was dropped before reaching the parser, with no error. File arguments that exist on disk are now taken literally; only non-existent paths are globbed, so shell-style wildcards still expand. Also adds "postgresql" to _KNOWN_SECTIONS so PARSEDMARC_POSTGRESQL_* env vars (and their _FILE Docker-secret variants) resolve like every other backend -- the PostgreSQL backend is new in 10.0.0, so this completes the unreleased feature rather than fixing a released regression, and is documented under the PostgreSQL enhancement, not Bug fixes. Regression tests added for both. Verified end-to-end: all four samples/failure/*.eml now index (the bracketed Netease report included). Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com> * dev: validate dashboards on OpenSearch 3.x and add PostgreSQL to the dev stack The dev stack ran OpenSearch Dashboards 3.x against OpenSearch 2.x, an unsupported cross-major pairing. Bump opensearch to :3 (validated on 3.6.0: OSD import into the Global tenant and all dashboards work). Add a postgresql service plus bootstrap wiring so the new PostgreSQL backend is exercised alongside the others: wait for PG, seed it via PARSEDMARC_POSTGRESQL_* env vars on the same parsedmarc run, wipe it on RESEED, create a Grafana grafana-postgresql-datasource (uid dmarc-pg), and import dashboards/grafana/Grafana-DMARC_Reports-PostgreSQL.json. PG seeding is gated on psycopg being importable: parsedmarc aborts the whole run (exit 1, nothing written to any backend) when a configured output backend can't initialize, so wiring in PG without the optional extra would silently zero ES/OS/Splunk too. When psycopg is absent the script warns and skips PG, leaving the other backends seeded. Also fix the Grafana admin password env: the container was given GRAFANA_PASSWORD, which Grafana ignores -- it reads GF_SECURITY_ADMIN_PASSWORD. Defaults to admin to match the script. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com> * docs: list PostgreSQL on the premade-dashboards features bullet PostgreSQL ships a premade Grafana dashboard (dashboards/grafana/Grafana-DMARC_Reports-PostgreSQL.json), so it belongs on the "for use with premade dashboards" bullet alongside Elasticsearch, OpenSearch, and Splunk rather than on the plain-output-destinations line. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com> * fix: clear stale org_email mapping conflict in the OpenSearch dashboards The aggregate index pattern in dashboards/opensearch/opensearch_dashboards.ndjson shipped a cached field-list snapshot where org_email was a text/object conflict, plus leftover org_email.#text and org_email.#text.keyword subfields. Those came from a cluster that had indexed a langAttrString email dict ({"#text": ..., "@lang": ...}) before the parser unwrapped it. org_email is mapped as Text() and parse_aggregate_report_xml now unwraps a dict email to a plain string, so current data is consistently text -- a clean cluster's _field_caps reports no conflict. Cleared the frozen conflict and the two artifact subfields, leaving org_email (text) and org_email.keyword, matching the live mapping. Verified: re-importing the corrected ndjson yields an index pattern with org_email as a plain text field and zero conflicts; only the aggregate index-pattern line changed, all other saved objects byte-identical. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com> * dev: seed the RFC 9990 (dmarc-2.0) aggregate samples samples/aggregate/rfc9990-sample.xml and rfc9990-example.net!...xml were not in the bootstrap's SAMPLE_FILES, so the dev stack only ever indexed RFC 7489 reports and the new DMARCbis fields (np, testing, discovery_method, generator, xml_namespace) never appeared in the OpenSearch/Kibana indices or were available to the dashboards. Added both samples (one declares the urn:ietf:params:xml:ns:dmarc-2.0 namespace, the other is namespaceless RFC 9990-shaped, covering both detection paths). Verified the seeded data now carries np/testing/ discovery_method/generator and xml_namespace=urn:ietf:params:xml:ns:dmarc-2.0; OpenSearch Dashboards surfaces them on an index-pattern field-list refresh. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com> * dev: auto-resolve (or create) a venv for the seed and ensure psycopg The seed previously required parsedmarc to be pre-installed and only warned-and-skipped PostgreSQL when psycopg was missing. Resolve the seed environment by precedence instead: 1. explicit PARSEDMARC_BIN -> used as-is, nothing installed 2. active $VIRTUAL_ENV 3. existing repo venv/ or .venv/ 4. otherwise create $REPO_ROOT/venv For cases 2-4, run `pip install -e .[postgresql]` only when the CLI or psycopg is missing, so the dev stack can populate Postgres out of the box without a manual install step. The explicit-PARSEDMARC_BIN path is left untouched (and the psycopg seed guard still warns/skips if that env lacks the extra). Verified: a RESEED run resolves the active venv, seeds ES/OS/Splunk/PG including the RFC 9990 fields, with no output-client errors. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com> --------- Co-authored-by: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
3.0 KiB
3.0 KiB
parsedmarc
![]()
![]()


parsedmarc is a Python module and CLI utility for parsing DMARC
reports. When used with Elasticsearch and Kibana (or Splunk), it works
as a self-hosted open-source alternative to commercial DMARC report
processing services such as Agari Brand Protection, Dmarcian, OnDMARC,
ProofPoint Email Fraud Defense, and Valimail.
Note
Domain-based Message Authentication, Reporting, and Conformance (DMARC) is an email authentication protocol.
Sponsors
This is a project is maintained by one developer. Please consider sponsoring my work if you or your organization benefit from it.
Features
- Parses aggregate/rua DMARC reports: the legacy draft and 1.0 schemas (RFC 7489) and the new RFC 9990 schema for the final DMARC standard (RFC 9989)
- Parses failure/ruf DMARC reports (RFC 6591 and RFC 9991; formerly called forensic reports)
- Parses reports from SMTP TLS Reporting (TLS-RPT, RFC 8460)
- Can parse reports from an inbox over IMAP, Microsoft Graph, or Gmail API
- Transparently handles gzip or zip compressed reports
- Consistent data structures
- Simple JSON and/or CSV output
- Optionally email the results
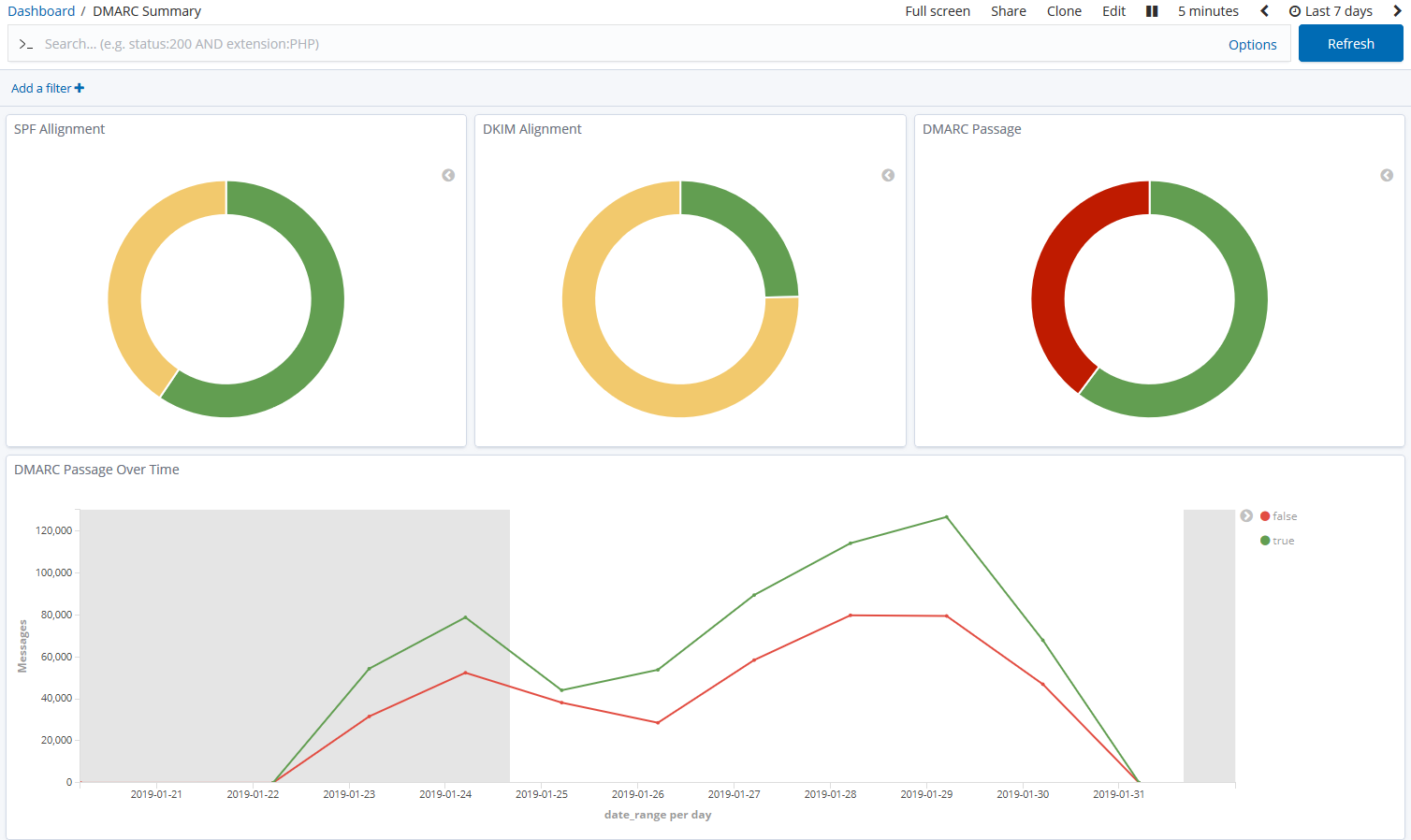
- Optionally send the results to Elasticsearch, OpenSearch, Splunk, or PostgreSQL, for use with premade dashboards
- Optionally send the results to Apache Kafka, Amazon S3, Azure Log Analytics (Microsoft Sentinel), a Graylog (GELF) endpoint, a syslog server, or an HTTP webhook
Python Compatibility
This project supports the following Python versions, which are either actively maintained or are the default versions for RHEL or Debian.
| Version | Supported | Reason |
|---|---|---|
| < 3.6 | ❌ | End of Life (EOL) |
| 3.6 | ❌ | Used in RHEL 8, but not supported by project dependencies |
| 3.7 | ❌ | End of Life (EOL) |
| 3.8 | ❌ | End of Life (EOL) |
| 3.9 | ❌ | Used in Debian 11 and RHEL 9, but not supported by project dependencies |
| 3.10 | ✅ | Actively maintained |
| 3.11 | ✅ | Actively maintained; supported until June 2028 (Debian 12) |
| 3.12 | ✅ | Actively maintained; supported until May 2035 (RHEL 10) |
| 3.13 | ✅ | Actively maintained; supported until June 2030 (Debian 13) |
| 3.14 | ✅ | Supported (requires imapclient>=3.1.0) |